Robots.txt to plik tekstowy umieszczony w głównym katalogu domeny (twojadomena.pl/robots.txt), który mówi robotom wyszukiwarek, które części witryny mogą crawlować, a których powinny unikać. To jeden z najstarszych mechanizmów kontroli crawlowania w historii internetu – Robots Exclusion Protocol istnieje od 1994 roku i został sformalizowany jako standard RFC 9309 w 2022 roku. Według danych Ahrefs, fraza „robots.txt” generuje w Polsce 600 wyszukiwań miesięcznie (KD 71), a „robots txt” kolejne 200 (KD 67), co pokazuje stabilny i konkurencyjny popyt na ten temat. Google wyświetla AI Overview w SERP dla obu fraz.
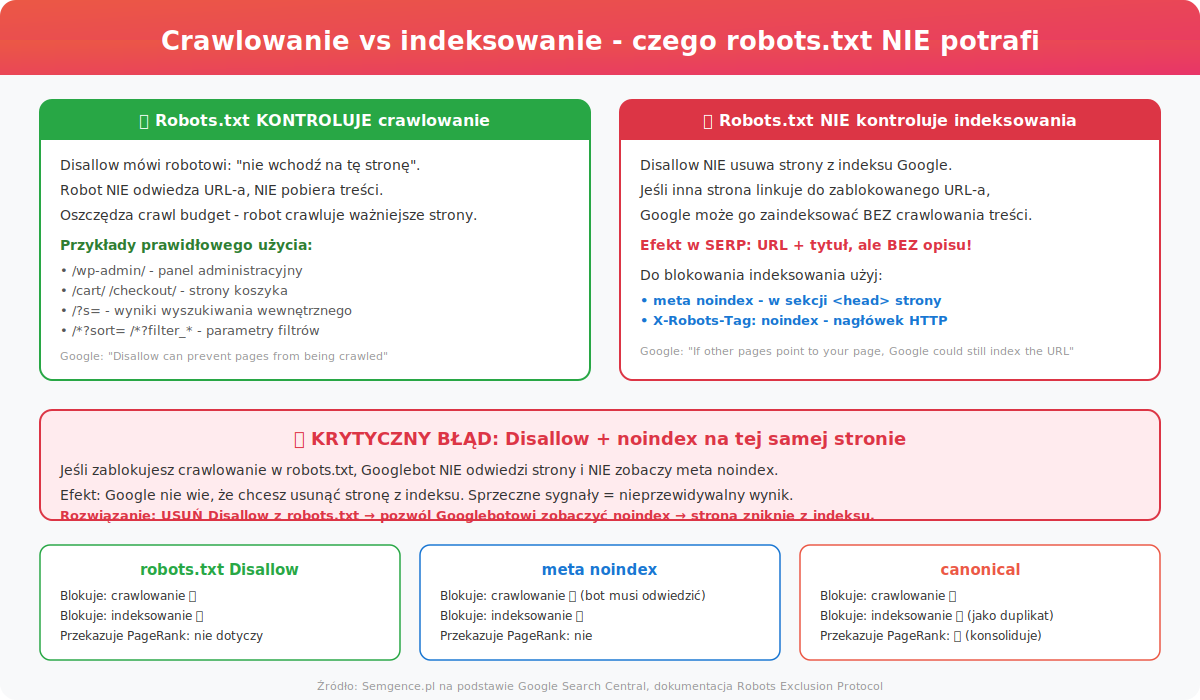
Ale uwaga – to kluczowe rozróżnienie, które wielu właścicieli stron myli: robots.txt kontroluje crawlowanie (czy robot odwiedzi stronę), ale nie indeksowanie (czy strona pojawi się w wynikach Google). Jak wyjaśnia oficjalna dokumentacja Google: jeśli inne strony linkują do URL-a zablokowanego w robots.txt, Google może go zaindeksować bez crawlowania treści. Jeśli chcesz zablokować indeksowanie – potrzebujesz meta noindex, nie robots.txt.
W 2026 roku robots.txt zyskał zupełnie nowy wymiar: kontrolowanie dostępu botów AI do treści. GPTBot, ClaudeBot, PerplexityBot, Google-Extended – każdy z tych crawlerów wymaga świadomej decyzji: blokować (chroniąc IP) czy zezwalać (zachowując widoczność w AI Search). Semgence – agencja SEO z Warszawy – analizuje konfigurację robots.txt jako jeden z pierwszych kroków każdego audytu SEO, ze szczególnym uwzględnieniem polityki wobec botów AI.
Jak działa robots.txt?
Gdy Googlebot (lub inny crawler) odwiedza Twoją stronę, pierwszą rzeczą, którą sprawdza, jest plik robots.txt pod adresem twojadomena.pl/robots.txt. Zanim robot pobierze jakąkolwiek podstronę, analizuje reguły w tym pliku i decyduje, które ścieżki może crawlować. To zachowanie jest zgodne z Robots Exclusion Protocol – standardem, który od 1994 roku określa, jak roboty powinny interpretować ten plik.
Sam plik ma prostą składnię tekstową. Każda sekcja zaczyna się od dyrektywy User-agent:, która określa, do którego robota odnoszą się następujące reguły. Gwiazdka (*) oznacza wszystkie roboty, ale możesz wskazać konkretnego: Googlebot, Bingbot, GPTBot. Po User-agent następują dyrektywy Disallow: (blokuj tę ścieżkę) i Allow: (zezwól na tę ścieżkę jako wyjątek od Disallow). Na końcu pliku zwyczajowo umieszcza się dyrektywę Sitemap: wskazującą lokalizację mapy strony XML – to nie jest dyrektywa crawlowania, ale wskazówka, która pomaga robotowi znaleźć strukturę serwisu.
Ważny niuans techniczny: Google traktuje robots.txt jako dyrektywę crawlowania, nie indeksowania. Jeśli zablokujesz URL w robots.txt, Googlebot go nie odwiedzi – ale jeśli inna strona (np. zewnętrzna witryna) linkuje do tego URL-a, Google może go zaindeksować na podstawie samego linku, bez crawlowania treści. W wynikach wyszukiwania pojawi się wtedy wpis z URL-em i ewentualnie tytułem pobranym z anchor textu linku, ale bez opisu – bo Google nie odwiedził strony i nie zna jej zawartości.

Co blokować w robots.txt?
Robots.txt służy przede wszystkim do oszczędzania crawl budgetu – żeby Googlebot nie marnował czasu na strony, które nie powinny się znaleźć w wynikach wyszukiwania. Na typowej stronie WordPress z WooCommerce do zablokowania jest kilka standardowych ścieżek.
Panel administracyjny (/wp-admin/, /admin/, /panel/) nie powinien być crawlowany – to strony logowania i zarządzania treścią, które nie mają wartości dla użytkowników wyszukiwarki. Jedyny wyjątek: plik /wp-admin/admin-ajax.php, którego WordPress używa do dynamicznego ładowania treści – blokowanie go może uniemożliwić Google prawidłowe renderowanie strony.
Koszyk i checkout (/cart/, /checkout/, /my-account/) to strony transakcyjne specyficzne dla sesji użytkownika. Każdy użytkownik widzi inny koszyk – crawlowanie tych stron to marnowanie zasobów. W sklepach e-commerce mogą to być tysiące URL-i parametrowych, które nie wnoszą nic do indeksu.
Wyniki wyszukiwania wewnętrznego (/?s=, /search/) to klasyczny generator duplikatów. Każde zapytanie tworzy nowy URL z identycznym szablonem strony. Google wyraźnie rekomenduje blokowanie tych stron w robots.txt – w przeciwnym razie Googlebot może generować tysiące żądań do wyszukiwarki wewnętrznej, marnując crawl budget i potencjalnie obciążając serwer.
Parametry filtrowania i sortowania (/*?sort=, /*?filter_*, /*?orderby=) w e-commerce tworzą kombinatoryczną eksplozję URL-i z niemal identyczną treścią. Blokowanie tych parametrów w robots.txt to pierwszy poziom ochrony crawl budgetu, a canonical na czysty URL kategorii – drugi.
Czego absolutnie NIE blokować: plików CSS i JavaScript. Google potrzebuje ich do renderowania strony i zrozumienia jej treści. Jak podkreśla dokumentacja Google: blokowanie CSS/JS może uniemożliwić Google prawidłowe zrozumienie treści strony, co prowadzi do gorszych pozycji w wynikach. To błąd, który nadal widzimy w audytach – pozostałość po starych poradnikach SEO z czasów, gdy Google nie renderował JS.
Robots.txt a blokowanie indeksowania – czego nie potrafi?
To najczęstszy mit w SEO: robots.txt NIE blokuje indeksowania. Disallow mówi robotowi „nie wchodź na tę stronę” – ale jeśli inna strona linkuje do zablokowanego URL-a, Google może go zaindeksować bez crawlowania treści. W wynikach wyszukiwania pojawi się wtedy wpis z tytułem i URL-em, ale bez opisu – bo Google nie odwiedził strony i nie zna jej zawartości. To tzw. „blind indexing” i zdarza się częściej niż mogłoby się wydawać.
Jeśli chcesz naprawdę zablokować indeksowanie strony, masz dwa narzędzia. Pierwsze to meta noindex – tag <meta name="robots" content="noindex"> umieszczony w sekcji <head> strony. To dyrektywa, którą Google respektuje: strona z noindex zostanie usunięta z indeksu, nawet jeśli inne strony do niej linkują. Drugie narzędzie to X-Robots-Tag – nagłówek HTTP X-Robots-Tag: noindex, przydatny dla zasobów bez sekcji HTML <head> (pliki PDF, obrazy, dokumenty).
Krytyczny błąd, który widzimy w audytach: łączenie Disallow w robots.txt z meta noindex na tej samej stronie. Logika wydaje się sensowna („zablokuję crawlowanie I indeksowanie”), ale w praktyce to sprzeczne sygnały. Jeśli zablokujesz crawlowanie w robots.txt, Googlebot nie odwiedzi strony – a więc nie zobaczy meta noindex. Google nie wie, że chcesz usunąć stronę z indeksu. Rozwiązanie: usuń Disallow z robots.txt, pozwól Googlebotowi odwiedzić stronę i zobaczyć noindex – wtedy strona zniknie z indeksu.
Robots.txt a boty AI – GPTBot, ClaudeBot, Google-Extended
Od 2024 roku robots.txt zyskał zupełnie nowy wymiar: kontrolowanie dostępu botów AI do treści Twojej strony. Ekosystem crawlerów AI rozrósł się do ponad 12 botów od 6 organizacji, a każdy z nich wymaga świadomej decyzji: blokować czy zezwalać. To nie jest pytanie akademickie – według analizy Cloudflare z Q1 2026, GPTBot jest blokowany przez 5,2% domen z robots.txt, a odsetek rośnie z kwartału na kwartał.
Kluczowe rozróżnienie, którego brakuje w większości poradników: boty AI dzielą się na treningowe (zbierają dane do trenowania modeli) i search/retrieval (pobierają treść w czasie rzeczywistym, żeby odpowiedzieć na pytanie użytkownika). To dwie zupełnie różne kategorie z różnymi implikacjami biznesowymi.
Boty treningowe (GPTBot, ClaudeBot, CCBot, Meta-ExternalAgent, Bytespider) pobierają Twoje treści, żeby wzbogacić bazę wiedzy modelu AI. Blokowanie ich chroni Twoją własność intelektualną – Twoje treści nie będą wykorzystane do trenowania modeli, których nie kontrolujesz. Ale jest koszt: jeśli zablokujesz GPTBot, ChatGPT nie będzie miał Twoich treści w bazie wiedzy i rzadziej Cię zacytuje.
Boty search/retrieval (OAI-SearchBot, ChatGPT-User, PerplexityBot, Claude-SearchBot) pobierają treść na żywo, gdy użytkownik zadaje pytanie w ChatGPT Search, Perplexity czy Claude. Blokowanie tych botów oznacza, że Twoja strona znika z odpowiedzi AI – a według danych Superlines, ruch z AI Search konwertuje 4,4x lepiej niż standardowy organic. Zezwalanie na te boty generuje realne odsłony i cytowania.
Strategia hybrydowa, którą rekomendujemy klientom Semgence: blokuj boty treningowe (chroniąc IP), zezwalaj na boty search (zachowując widoczność). Jak podkreśla szczegółowy poradnik Soar Agency o botach AI: „Most brands’ robots.txt files are three years behind the current AI bot landscape.” Więcej o widoczności w AI opisujemy w artykule o audycie widoczności w AI.
Ważne zastrzeżenie dotyczące Perplexity: Cloudflare udokumentował w sierpniu 2025 roku, że Perplexity używa niezadeklarowanych crawlerów, które rotują user-agenty i adresy IP, omijając reguły robots.txt. Blokowanie Perplexity na poziomie robots.txt nie jest w pełni skuteczne – jedyną pewną ochroną jest blokowanie na poziomie serwera (WAF).

Przykładowy plik robots.txt – WordPress + WooCommerce
Poniżej optymalny robots.txt dla typowej strony WordPress z WooCommerce, uwzględniający zarówno klasyczne reguły SEO, jak i strategię wobec botów AI w 2026 roku. Ten plik stosuje podejście hybrydowe: blokuje boty treningowe, zezwala na boty search, chroni strony techniczne i oszczędza crawl budget.
# Robots.txt - WordPress + WooCommerce (2026)
# Opracowanie: Semgence.pl
# === Reguły dla wszystkich botów ===
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /cart/
Disallow: /checkout/
Disallow: /my-account/
Disallow: /?s=
Disallow: /search/
Disallow: /*?add-to-cart=*
Disallow: /*?orderby=*
Disallow: /*?filter_*
# === Boty AI - TRENING (blokujemy) ===
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
# === Boty AI - SEARCH (zezwalamy) ===
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: PerplexityBot
Allow: /
# === Mapa strony ===
Sitemap: https://www.twojadomena.pl/sitemap_index.xmlPo każdej zmianie robots.txt przetestuj go w narzędziu do testowania robots.txt w Google Search Console. Warto też pamiętać, że Google cachuje robots.txt – po edycji zmiany mogą zacząć obowiązywać dopiero po kilku godzinach, gdy Google ponownie pobierze plik.
Jak sprawdzić robots.txt swojej strony?
Weryfikacja robots.txt to jeden z prostszych elementów audytu technicznego, ale wymaga kilku perspektyw.
Bezpośrednio w przeglądarce – wpisz twojadomena.pl/robots.txt. Jeśli widzisz plik tekstowy z dyrektywami User-agent i Disallow – jest skonfigurowany. Jeśli widzisz stronę 404 – plik nie istnieje, co jest technicznie OK: Google traktuje brak pliku robots.txt jako pozwolenie na crawlowanie całej witryny. Ale brak pliku oznacza też brak kontroli nad botami AI.
Google Search Console oferuje narzędzie do testowania robots.txt, które pozwala sprawdzić, czy konkretny URL jest zablokowany dla Googlebota. Wpisujesz URL – narzędzie pokazuje, która reguła go blokuje (lub potwierdza, że jest dozwolony). To jedyny sposób, żeby zobaczyć, jak Google interpretuje Twoje reguły, bo składnia robots.txt ma niuanse (np. kolejność reguł ma znaczenie dla Google).
Screaming Frog SEO Spider automatycznie sprawdza robots.txt przy każdym crawlu i oznacza zablokowane URL-e w raporcie. To szczególnie przydatne przy dużych serwisach, gdzie ręczne sprawdzanie byłoby niepraktyczne. Screaming Frog pokazuje też, które reguły blokują które URL-e – łatwo zidentyfikujesz zbyt szerokie Disallow, które przypadkowo blokują ważne strony.
Więcej o narzędziach do audytu technicznego opisujemy w checkliście technicznego SEO oraz w naszym ebooku „Co powinien zawierać audyt SEO”.
Najczęstsze błędy w robots.txt
Blokowanie CSS i JavaScript to relikt starych praktyk SEO, który nadal widzimy w audytach. Kiedyś blokowanie tych zasobów było standardem – dziś Google potrzebuje CSS i JS do renderowania strony. Bez nich Google widzi „gołą” wersję HTML i nie rozumie layoutu, treści ładowanych dynamicznie ani interaktywnych elementów. Efekt: gorsze pozycje, bo Google nie jest w stanie ocenić jakości strony.
Przypadkowe zablokowanie całej strony to błąd, który brzmi absurdalnie, ale zdarza się częściej niż myślisz. Jedna literówka – Disallow: / pod User-agent: * – blokuje WSZYSTKO. Jeden błąd w edycji pliku i Google nie crawluje żadnej strony w serwisie. Jak opisuje Paweł Gontarek na liście 20 najczęstszych błędów SEO (Zgred.pl), to zaskakująco częsty problem przy migracjach – plik robots.txt z wersji deweloperskiej (który ma Disallow: /, żeby Google nie indeksował staging) jest przenoszony na produkcję bez modyfikacji.
Łączenie Disallow z meta noindex to sprzeczne sygnały, o których pisaliśmy wyżej. Googlebot nie odwiedza strony (Disallow), więc nie widzi noindex. Strona pozostaje w indeksie, choć właściciel myśli, że jest z niego usunięta. Rozwiązanie: wybierz jedno – albo Disallow (blokujesz crawlowanie, ale ryzykujesz blind indexing), albo noindex (zezwalasz na crawlowanie, ale blokujesz indeksowanie).
Brak dyrektywy Sitemap nie blokuje indeksowania, ale wskazanie sitemap w robots.txt to najszybszy sposób, żeby roboty znalazły Twoją mapę strony. Bez tego Google musi odkryć sitemap przez linki wewnętrzne lub przez wpis w Google Search Console – co może trwać dłużej.
Nieaktualna polityka wobec botów AI to nowy rodzaj błędu w 2026 roku. Większość stron ma robots.txt napisany w 2020-2022 – bez żadnych reguł dla GPTBot, ClaudeBot czy Google-Extended. Efekt: boty AI mają nieograniczony dostęp do wszystkich treści, co może oznaczać, że Twoje artykuły są wykorzystywane do trenowania modeli bez Twojej zgody. Regularne aktualizowanie robots.txt pod kątem nowych botów to element, który powinien być częścią kwartalnego przeglądu technicznego.
Najczęściej zadawane pytania o robots.txt
Czy robots.txt blokuje indeksowanie strony?
Nie. Robots.txt blokuje crawlowanie (odwiedzanie strony przez robota), ale nie indeksowanie. Jeśli inna strona linkuje do URL zablokowanego w robots.txt, Google może go zaindeksować bez crawlowania treści. Do blokowania indeksowania użyj meta noindex lub nagłówka X-Robots-Tag: noindex.
Co się stanie jeśli nie mam pliku robots.txt?
Google traktuje brak pliku robots.txt jako pozwolenie na crawlowanie całej witryny. Plik jest opcjonalny – ale zalecany, bo pozwala kontrolować crawl budget, blokować dostęp do stron technicznych i definiować politykę wobec botów AI. W 2026 roku brak robots.txt oznacza też brak jakiejkolwiek kontroli nad tym, które boty AI crawlują Twoje treści.
Czy mogę zablokować boty AI (ChatGPT, Gemini) w robots.txt?
Tak. Dodaj reguły Disallow dla GPTBot (OpenAI), ClaudeBot (Anthropic), Google-Extended (Gemini). Blokowanie tych botów nie wpływa na Googlebot – Twoja strona nadal będzie widoczna w wynikach wyszukiwania Google. Ale pamiętaj o rozróżnieniu: blokowanie botów treningowych (GPTBot, ClaudeBot) chroni IP, blokowanie botów search (OAI-SearchBot, PerplexityBot) usuwa Cię z odpowiedzi AI Search.
Czy mogę blokować CSS i JavaScript w robots.txt?
Technicznie tak, ale zdecydowanie nie powinieneś. Google potrzebuje CSS i JS do renderowania strony i zrozumienia jej treści. Blokowanie tych zasobów uniemożliwia Google prawidłowe rendering i może prowadzić do gorszych pozycji w wynikach. To pozostałość starych praktyk SEO – w 2026 roku blokowanie CSS/JS to aktywny błąd.
Jak przetestować plik robots.txt?
W Google Search Console znajdziesz narzędzie do testowania robots.txt. Wklej URL strony – narzędzie pokaże, czy jest zablokowana i przez którą regułę. W Screaming Frog raport automatycznie oznacza URL-e zablokowane przez robots.txt. Ręcznie: wejdź na twojadomena.pl/robots.txt i przeczytaj reguły.
Gdzie umieścić plik robots.txt?
W głównym katalogu domeny – twojadomena.pl/robots.txt. Nie w podkatalogach – plik w /blog/robots.txt nie będzie działać. W WordPress plik jest generowany automatycznie – możesz go edytować przez wtyczkę Rank Math (Ustawienia → Ogólne → Edycja robots.txt) lub Yoast SEO (Narzędzia → Edytor plików). Możesz też edytować go bezpośrednio przez FTP/SSH w katalogu głównym.
Czy robots.txt wpływa na widoczność w AI Search?
Tak – bezpośrednio. Blokowanie botów AI w robots.txt usuwa Twoją stronę z odpowiedzi ChatGPT, Claude, Perplexity i innych platform AI. To świadoma decyzja: chronisz IP kosztem widoczności. Strategia hybrydowa (blokuj trening, zezwalaj na search) pozwala zachować widoczność w AI bez udostępniania treści do trenowania modeli. Więcej o tym podejściu opisujemy w artykule o widoczności w AI.
Co to jest robots.txt?
Robots.txt to plik tekstowy w katalogu głównym strony (example.com/robots.txt), który informuje roboty wyszukiwarek, które części serwisu mogą crawlować, a których nie. Nie blokuje indeksacji – do tego służy meta robots noindex. Robots.txt kontroluje crawl budget.
Jak skonfigurować robots.txt?
Podstawowy robots.txt zawiera: User-agent (który bot), Disallow (co blokować), Allow (wyjątki od blokad) i Sitemap (ścieżka do sitemap.xml). W WordPress Rank Math generuje robots.txt automatycznie. Nie blokuj CSS i JS – Google musi je widzieć do renderowania strony.
Czy robots.txt blokuje indeksację?
Nie – robots.txt blokuje crawlowanie, nie indeksację. Jeśli zablokujesz stronę w robots.txt, ale inne strony do niej linkują, Google może ją zaindeksować (z pustym snippetem). Do blokowania indeksacji użyj meta robots noindex lub nagłówka HTTP X-Robots-Tag: noindex.