Systemy AI – ChatGPT, Perplexity, Gemini, Google AI Overviews – nie cytują losowych stron internetowych. Przechodzą przez wieloetapowy pipeline selekcji, w którym na każdym kroku odpada 80-90% kandydatów. Z setek stron dostępnych w indeksie webowym AI wybiera 3-5 źródeł do cytowania w odpowiedzi. Mechanizm tego wyboru opiera się na sygnałach, które możesz kontrolować: extractability treści, gęstość faktow, autorytet domeny, spójność encji i potwierdzenie informacji przez niezależne źródła. Ten artykul rozbiera caly pipeline na części – od pytania użytkownika do cytatu w odpowiedzi AI.
W Semgence monitorujemy widoczność w AI od ponad roku. Odpytaliśmy ponad 9000 razy pięć silników AI na 42 zapytaniach i zebraliśmy dane, których nie ma w żadnym publicznym badaniu. Ten artykuł nie jest kolejnym „przewodnikiem po GEO” – to raport z frontu, oparty na patentach Google, dokumentacji OpenAI i naszych własnych danych z monitoringu.
Jak wygląda pipeline od pytania użytkownika do cytatu?
Gdy użytkownik zadaje pytanie systemowi AI (np. „jaki robot kuchenny kupic do 1500 zl”), uruchamia się proces znany jako RAG – Retrieval-Augmented Generation. Według analizy Search Engine Land (2026), która obejmowała dekompilację aplikacji ChatGPT i analizę ruchu sieciowego, pipeline składa się z pieciu etapow:
- Query understanding i fan-out – AI rozkłada pytanie na intencję i generuje 3-8 podzapytań (patent US20250245255A1). „Jaki robot kuchenny kupic” staje sie: „najlepszy robot kuchenny 2026”, „robot kuchenny planetarny vs wielofunkcyjny”, „robot kuchenny do 1500 zl ranking”. To mechanizm query fan-out (opisany w artykule o faceted navigation).
- Retrieval – przeszukanie indeksu – dla każdego podzapytańia AI przeszukuje indeks webowy. ChatGPT używa indeksu Bing (nie Google), Gemini używa Google Search, Perplexity ma własny indeks. System pobiera 50-100 kandydatów. Jeśli Twoja strona nie jest w indeksie odpowiedniej wyszukiwarki, odpada na starcie.
- Content retrieval – pobranie treści – z kandydatów AI pobiera pełną treść 10-20 najwyżej ocenionych stron. Timeout wynosi okolo 2 sekund, OAI-SearchBot nie renderuje JavaScript. Treść jest dzielona na fragmenty (~128 tokenów) i oceniana pod katem dopasowania.
- Ranking i scoring – AI ocenia każdy fragment: extractability, fact density, source authority, freshness, consensus. Z 10-20 stron zostaje 3-5.
- Generation i citation assignment – LLM generuje odpowiedz, wplatajac informacje ze źródeł. Cytat jest przypisany tylko gdy konkretne twierdzenie pochodzi bezposrednio z danego źródła.

Wniosek, który zmienia perspektywę: 80% gry rozgrywa się na etapach 1-3 (retrieval). Jeśli Twoja strona nie trafia do puli kandydatów, najlepsza treść nie pomoże. Techniczne fundamenty (dostępność dla botów AI, szybkosc, indeksacja w Bing) sa warunkiem koniecznym, nie wystarczajacym.
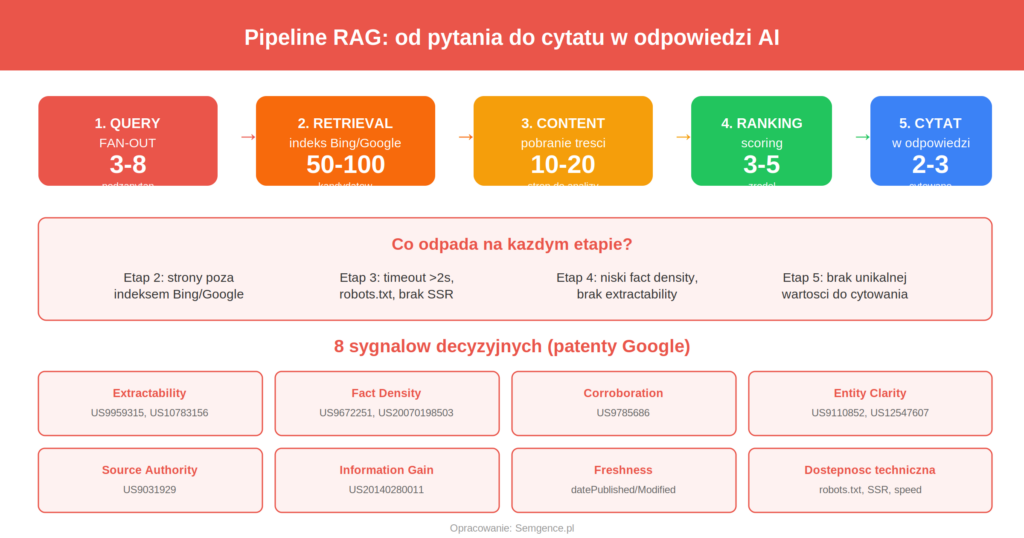
Jakie sygnały decydują o cytowaniu? Analiza patentów Google
Analizując patenty Google, dokumentację OpenAI i własne dane z monitoringu AI (ponad 9000 uruchomień promptów), wyodrębniliśmy osiem ośmiu sygnałów. Każdy odpowiada konkretnemu wzorcowi patentówemu.
1. Extractability – czy AI łatwo wyciaga odpowiedz?
Patenty US9959315B1 i US10783156B1 opisują mechanizm „answer display eligibility” – system sprawdza, czy fragment tekstu może zostac wyświetlony jako samodzielna odpowiedz. Strona zaczynająca od „Nasza firma od 20 lat z pasja…” przegrywa ze strona która zaczyna od „Robot kuchenny planetarny kosztuje 800-2500 zl. Najlepsze modele to Bosch MUM5 i KitchenAid Artisan”. AI potrzebuje odpowiedzi w pierwszych 128 tokenach – bo to wielkość fragmentu, na podstawie którego system decyduje, czy warto czytac reszte. Więcej o formacie answer-first opisujemy w kontekscie extractability score.
Weźmy dwie strony, które odpowiadają na „ile kosztuje pozycjonowanie sklepu”. Pierwszy serwis zaczyna od historii firmy – odpowiedź pojawia się w trzecim akapicie. Drugi serwis zaczyna: „Pozycjonowanie sklepu internetowego kosztuje 2000-15 000 zł miesięcznie w zależności od wielkości sklepu i konkurencyjności branży.” AI wybierze stronę B – odpowiedź mieści się w oknie 128 tokenów, które system ocenia jako „audition chunk”.
Praktyczny przykład: dwie strony odpowiadają na pytanie „ile kosztuje pozycjonowanie sklepu internetowego”. Pierwszy serwis zaczyna od historii firmy i ogólnych frazesów o SEO – odpowiedź na pytanie pojawia się dopiero w trzecim akapicie. Strona B zaczyna od: „Pozycjonowanie sklepu internetowego kosztuje 2000-15 000 zł miesięcznie w zależności od wielkości sklepu, konkurencyjności branży i zakresu prac.” AI wybierze stronę B, bo odpowiedź jest w pierwszych 20 słowach – mieści się w oknie 128 tokenów, które system ocenia jako „audition chunk”.
2. Fact density – ile weryfikowalnych faktow na 100 slow?
Patenty US9672251B1 i US20070198503A1 opisują „entity fact density” – gęstość weryfikowalnych faktow (liczby, daty, nazwy, porównania) w treści strony. Zdanie „jestesmy liderem branzy” ma fact density = 0. Zdanie „obsługujemy 340 klientow w 12 branżach, sredni czas realizacji to 14 dni” ma fact density = 4 fakty. AI preferuje źródła z wysoka gęstościa faktow, bo może je zweryfikowac krzyzowo z innymi źródłami.
3. Corroboration – czy inne źródła potwierdzają te same fakty?
Patent US9785686B2 opisuje mechanizm „fact corroboration” – system sprawdza, czy informacja na Twojej stronie jest potwierdzona przez niezależne źródła. Jeśli trzy rozne strony podaja, ze „robot kuchenny Bosch MUM5 kosztuje 899 zl i ma moc 1000W”, ta informacja dostaje wysoki confidence score. Jeśli tylko Twoja strona podaje konkretna cene – confidence jest niższy. Dlatego sprzedawcy cytujący dane producenta (specyfikacje, parametry) maja przewage nad stronami z własnymi, niezweryfikowanymi twierdzeniami.
4. Entity clarity – czy AI rozumie, o czym jest Twoja strona?
Patenty US9110852B1 (EAV fact extraction) i US12547607B2 (verified entity attributes) opisują, jak systemy wyodrębniają trójki encja-atrybut-wartość z treści. Strona musi jednoznacznie definiowac: o jakiej encji mowi (Product? Brand? Category?), jakie atrybuty opisuje (cena, moc, wymiary) i jakie wartośći im przypisuje. Schema markup (JSON-LD) drastycznie ulatwia ten proces – AI nie musi „zgadywac” relacji miedzy encjami, bo sa jawnie zadeklarowane w strukturze danych.
5. Source authority – autorytet domeny i marki
Patent US9031929B1 opisuje „site quality score” bazujący na sygnałach jakościowych domeny: profil linkowy, popyt na markę (branded search queries), cytowalność w internecie. Według badania Ahrefs (2025, 75 000 marek), korelacja miedzy wzmiankami o marce w internecie a widocznościa w AI wynosi 0,664 – trzykrotnie więcej niz korelacja dla tradycyjnych backlinkow (0,218). To oznacza, ze obecność marki na Reddit, Quora, YouTube i w mediach branżowych ma wieksze znaczenie dla cytowania przez AI niz klasyczny link building.

6. Information gain – czy Twoja strona wnosi cos nowego?
Patent US20140280011A1 opisuje „predictive site quality” i „information gain” – czy strona dostarcza informacji, których nie ma na innych stronach o tym samym temacie. Jeśli 10 stron pisze „robot kuchenny miesi ciasto i miksuje”, a Twoja strona dodaje „robot kuchenny planetarny generuje sile ugniatania 3,5 kg, co odpowiada 20 minutom recznego wyrabiania” – Twoja strona ma wyższy information gain. AI preferuje źródła, które dodaja cos nowego do konwersacji, nie powtarzaja tego, co jest wszedzie.
7. Freshness – aktualność treści
Data publikacji i ostatniej aktualizacji wpływa na selekcję źródła. Artykul „Najlepsze roboty kuchenne 2024” przegrywa z „Najlepsze roboty kuchenne 2026” na pytanie zadane w 2026. AI sprawdza daty w meta tagach, schema markup (datePublished, dateModified) i w treści. Strony bez widocznej daty publikacji sa traktowane z mniejszym zaufaniem – system nie wie, czy informacje sa aktualne.
8. Dostępność techniczna – czy bot AI może w ogole dotrzeć do Twojej treści?
Według badania SE Ranking (2025), 73% stron internetowych blokuje przynajmniej jednego bota AI – czesto nieświadomie, przez zbyt restrykcyjne reguly robots.txt odziedziczone ze starych konfiguracji. ChatGPT używa trzech botów:
- GPTBot – crawler treningowy. Blokowanie go nie wpływa na cytowanie, ale może wpłynąć na to, co ChatGPT „wie” o Twojej marce.
- OAI-SearchBot – buduje indeks wyszukiwania ChatGPT Search. Zablokowanie = ChatGPT nigdy nie zacytuje Twojej strony w odpowiedziąch z wyszukiwania.
- ChatGPT-User – pobiera treść strony w czasie rzeczywistej rozmowy. Blokowanie = ChatGPT nie może przeczytac Twojej strony nawet jeśli ja znajdzie.
Jest jeszcze kilka wymagań technicznych: czas odpowiedzi serwera poniżej 2 sekund (timeout crawlera), renderowanie server-side (OAI-SearchBot nie renderuje JavaScript), brak paywall’a na treściach, które chcesz cytowac. Więcej o kontroli dostępu botów AI do strony opisujemy w kontekscie audytu widoczności w AI.
Czym różni się cytowanie w ChatGPT, Perplexity, Gemini i Google AIO?
Każdy system AI ma inny pipeline retrieval i inny sposób cytowania źródeł:
- ChatGPT (Search) – retrieval przez indeks Bing. Cytuje 3-5 źródeł z inline citations. OAI-SearchBot buduje indeks, ChatGPT-User pobiera treść. Preferuje strony z jasnym answer-first formatem i schema markup. Ważne: Twoja strona musi byc w Bing Webmaster Tools.
- Perplexity – najagresywniejszy w cytowaniu: 5-10 źródeł per odpowiedź z widocznymi snippetami. Wlasny crawler PerplexityBot. Preferuje strony z duza gęstościa faktow i jasnymi naglowkami H2. Linkuje bezposrednio do źródeł – wyższy potencjał ruchu niz ChatGPT.
- Gemini – retrieval przez Google Search, gleboko zintegrowany z Knowledge Graph. Preferuje strony z rozbudowanym schema markup i wysokim autorytetem w Google. Cytuje 3-5 źródeł, czesto z Google News i Wikipedia.
- Google AI Overviews – nie linkuje „źródeł” w tradycyjnym sensie, raczej „Dowiedz się więcej”. Bazuje na top 10 organicznych wynikow Google – jeśli nie rankujesz w top 10 na dana fraze, prawdopodobnie nie pojawisz się w AIO. Według danych Seer Interactive, AIO pojawia się w 48% zapytan informacyjnych.
Konfiguracja robots.txt, która pozwala na cytowanie w AI Search ale blokuje trening:
# Pozwol botom wyszukiwania AI
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
# Blokuj boty treningowe
User-agent: GPTBot
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Google-Extended
Disallow: /Ta konfiguracja daje kontrolę: treść może być cytowana w odpowiedziach AI (OAI-SearchBot, PerplexityBot), ale nie jest używana do treningu nowych modeli (GPTBot, CCBot). Według Practical Ecommerce, to rozróżnienie jest istotne dla wydawców chcących widoczności w AI Search bez oddawania treści na trening.
Jakie błędy najczęściej blokują cytowanie przez AI?
W audytach widoczności AI, które przeprowadziliśmy dla kilkudziesięciu polskich stron, najczęstsze błędy blokujące cytowanie:
- Blokada OAI-SearchBot w robots.txt – najczęstsza przyczyna. Reguła Disallow: / dla wszystkich botów. Fix: 30 sekund edycji pliku robots.txt.
- Brak indeksacji w Bing – ChatGPT używa Bing, nie Google. Strona na pozycji 1 w Google może być niewidoczna dla ChatGPT. Fix: Bing Webmaster Tools + sitemap.
- Client-side rendering (CSR) – OAI-SearchBot nie renderuje JavaScript. Treść w React/Vue/Angular bez SSR jest niewidoczna. Googlebot renderuje JS, ale inne boty AI nie.
- Odpowiedź ukryta na końcu artykułu – AI ocenia pierwsze 128 tokenów (audition chunk). 2000 słów wstępu przed odpowiedzią = strona pominięta.
- Brak schema markup – bez JSON-LD (Article, FAQPage, Product) AI musi zgadywać relacje między encjami. Z schema – relacje jawnie zadeklarowane.
- Treść za paywallem – boty AI nie logują się, nie akceptują cookies, nie przechodzą CAPTCHA. Treść za logowaniem = niewidoczna dla AI.
Co możesz zrobić, żeby AI cytowało Twoją stronę? 8 kroków z przykładami
Poniżej osiem konkretnych kroków z przykładami z realnych stron – od fundamentów technicznych po optymalizację treści:
Krok 1: Sprawdź robots.txt
Wejdź na twojadomena.pl/robots.txt i sprawdź, czy OAI-SearchBot nie jest zablokowany. Przykład prawidłowej konfiguracji z unv.org (strona ONZ ds. Wolontariuszy): osobne reguły dla OAI-SearchBot, PerplexityBot i bingbot – każdy bot ma zdefiniowane, co może crawlować, a co nie (np. /search/ zablokowane, reszta dostępna). Kontrprzykład: wiele polskich stron ma generyczne User-agent: * / Disallow: /, które blokuje WSZYSTKIE boty, włącznie z AI. Fix: 30 sekund edycji pliku.
Krok 2: Zarejestruj stronę w Bing Webmaster Tools
ChatGPT używa Bing jako silnika wyszukiwania, nie Google. Wpisz w ChatGPT dowolne zapytanie z Twojej branży i sprawdź, czy Twoja strona pojawia się w źródłach. Jeśli nie – wejdź na bing.com/webmasters, dodaj swoją domenę i prześlij sitemap.xml. Wyobraź sobie stronę rankującą na pozycji 1 w Google na „audyt SEO” może nie istnieć w Bing, jeśli nigdy nie została tam zgłoszona. Efekt: ChatGPT Search jej nie widzi, mimo że Google ją zna.
Krok 3: Wdróż format answer-first (BLUF)
Zobaczmy dwa sposoby odpowiedzi na pytanie „ile kosztuje pozycjonowanie strony”. Wersja A (typowa polska strona agencji): „W dzisiejszym dynamicznym świecie marketingu cyfrowego pozycjonowanie stron internetowych stało się kluczowym elementem strategii…” – odpowiedź na pytanie pojawia się dopiero po 400 słowach wstępu. Wersja B (format BLUF): „Pozycjonowanie strony internetowej kosztuje od 1500 do 15 000 zł miesięcznie. Cena zależy od trzech czynników: konkurencyjności branży, wielkości serwisu i zakresu prac.” AI wybierze wersję B, bo odpowiedź mieści się w oknie 128 tokenów.
Krok 4: Zwiększ fact density
Zobaczmy dwa opisy tej samej usługi. Wersja A (marketing): „Jesteśmy liderem branży SEO z wieloletnim doświadczeniem. Nasz zespół ekspertów zapewni Twojej firmie sukces w internecie.” Fact density = 0 (zero weryfikowalnych faktów). Wersja B (fakty): „Agencja obsługuje 127 klientów e-commerce w 14 branżach. Średni wzrost ruchu organicznego w pierwszym roku współpracy: 340%. Zespół liczy 18 specjalistów z certyfikatami Google Ads i Analytics.” Fact density = 5 (każda liczba jest weryfikowalna). AI może zweryfikować fakty z wersji B krzyżowo z innymi źródłami – ogólników z wersji A nie może.
Krok 5: Dodaj schema markup
Wejdź na search.google.com/test/rich-results i wpisz URL swojej strony. Jeśli wynik to „Brak elementów rozszerzonych” – AI musi zgadywać, czym jest Twoja strona. Dodaj minimum: Article (artykuły blogowe), FAQPage (strony z FAQ), Product i Offer (karty produktowe), Organization (strona O nas). Weźmy stronę z prawidłowym schema Article zawiera datePublished, author, publisher, headline – AI od razu wie kto napisał, kiedy, o czym. Bez schema – to anonimowa treść bez kontekstu.
Krok 6: Buduj entity paragraphs
Dodaj na najważniejszych stronach 2-3 zdania w trzeciej osobie opisujące Twoją firmę/produkt. Wzór z Wikipedii: „[Nazwa] jest [czym jest] z siedzibą w [miasto], założoną w [rok]. Specjalizuje się w [czym]. Obsługuje [ilu] klientów w [jakich branżach].” Przykład: „Semgence jest agencją SEO z siedzibą w Warszawie. Specjalizuje się w pozycjonowaniu sklepów internetowych i optymalizacji widoczności w systemach AI. Obsługuje klientów e-commerce w branżach sport, elektronika, dom i ogród.” Te zdania są łatwe do wyodrębnienia przez AI jako fakty o encji – mogą zostać bezpośrednio zacytowane.
Krok 7: Zadbaj o freshness
Wejdź na dowolną stronę w Google i sprawdź, czy przy wyniku widać datę. Strony z widoczną, aktualną datą (2026) wygrywają z niedatowanymi stronami i stronami z datami 2023-2024. W kodzie: dodaj datePublished i dateModified w schema Article. Na stronie: pokaż datę publikacji i datę ostatniej aktualizacji. Weźmy artykuł „Najlepsze narzędzia SEO” z datą „Aktualizacja: maj 2026” wygrywa z artykułem bez daty – AI nie wie, czy niedatowana treść jest aktualna czy sprzed 5 lat.
Krok 8: Buduj obecność marki poza własną stroną
Według badania Ahrefs (75 000 marek), korelacja wzmianek o marce w internecie z widocznością w AI wynosi 0,664 – trzykrotnie więcej niż korelacja tradycyjnych backlinków (0,218). Co to oznacza w praktyce? Zadaj ChatGPT pytanie: „[Twoja marka] opinie” lub „czy [Twoja marka] jest godna zaufania”. Jeśli AI nie potrafi odpowiedzieć – Twoja marka nie istnieje w kontekście, z którego AI czerpie wiedzę. Rozwiązanie: pisz gościnne artykuły na branżowych portalach, odpowiadaj na pytania na Quora i Reddit, publikuj na YouTube, bądź cytowany w mediach. AI szuka potwierdzenia autorytetu POZA Twoją stroną – nie wystarczy mówić o sobie dobrze na własnej stronie.
Jak monitorować, czy AI cytuje Twoją markę?
Monitorowanie widoczności w AI to świeża dyscyplina, która wymaga innych narzedzi niz tradycyjne SEO. Trzy podejscia:
- Ręcznie – zadaj 20-30 promptow w ChatGPT, Perplexity i Gemini związanych z Twoją branżą. Sprawdź: czy Twoja strona lub marka pojawia się w odpowiedziąch? Które źródła sa cytowane zamiast Ciebie?
- Automatycznie – narzedzia jak DataForSEO LLM Mentions API, Ahrefs Brand Radar lub dedykowany monitoring promptow. W Semgence monitorujemy widoczność klientow przez 7100+ uruchomien promptow w wielu silnikach AI.
- Metryki do śledzenia – citation rate (procent promptow z cytatem Twojej strony), share of voice (vs konkurencja), citation position (1. vs 5. źródło), engagement rate ruchu z AI Search (GA4).
Więcej o metodach monitorowania opisujemy w artykule o tym, jak mierzyć topical authority, który obejmuje również metryki AI visibility.
Case study: 9095 odpytań AI – co naprawdę decyduje o cytowaniu?
Przez 90 dni monitorowaliśmy widoczność naszego własnego serwisu w pięciu silnikach AI: ChatGPT, Perplexity, Gemini, Google AI Mode i Google AI Overviews. Łącznie 9095 uruchomień promptów na 42 zapytaniach. Wyniki nas zaskoczyły – pokazują konkretne mechanizmy selekcji źródeł – nie w teorii, a w mierzalnych liczbach.
Różne silniki, różne wyniki – na tym samym serwisie
Ten sam serwis, te same treści, te same 42 zapytania – a każdy silnik AI cytuje go z inną częstotliwością:
| Silnik AI | Visibility score | Brand rate | Citation rate |
|---|---|---|---|
| Google AI Mode | 25,8 / 100 | 23,4% | 38,0% |
| Gemini | 25,2 / 100 | 20,1% | 38,8% |
| Google AI Overviews | 20,4 / 100 | 17,8% | 30,0% |
| Perplexity | 14,7 / 100 | 13,6% | 20,7% |
| ChatGPT | 13,4 / 100 | 16,1% | 15,2% |
Gemini i Google AI Mode cytują ten serwis 2,5x częściej niż ChatGPT. Dlaczego? Bo Gemini i AI Mode używają indeksu Google – gdzie ten serwis ma silne pozycje organiczne. ChatGPT używa Bing – gdzie te same strony mają niższą widoczność. Kolejny dowód na to, o czym pisaliśmy w punkcie 2: bez indeksacji w Bing, ChatGPT Cię nie widzi.
Ten sam serwis, te same strony – ale radykalnie różna widoczność per temat
To, co nas uderzyło najbardziej: ten sam serwis ma visibility score od 0 do 83 w zależności od zapytania. Nie od silnika AI, nie od dnia tygodnia – od tego, jak dobrze konkretna strona odpowiada na konkretne pytanie.
Zapytania z wysoką widocznością (score 50-83):
- „Ile kosztuje szkolenie SEO w Polsce?” – score 53, citation rate 81%. Dlaczego działa: strona ma konkretną tabelę z cenami (3 warianty: 2900/4500/7500 zł), porównanie z konkurencją, FAQ z odpowiedziami na podzapytania. Wysoka fact density, format answer-first.
- „Jakie szkolenie SEO polecacie dla firm?” – score 63, brand rate 79%. Strona zawiera entity paragraph w trzeciej osobie opisujący ofertę szkoleniową. AI może bezpośrednio zacytować: „Semgence prowadzi szkolenia SEO dla firm – jednodniowe warsztaty, kurs 5-dniowy i mentoring indywidualny.”
- „Porównanie kursów SEO: papaSEO, Lexy, Semgence” – score 70, brand rate 97%. Prompt zawiera nazwę marki, więc AI aktywnie szuka informacji o niej. Ale wysoki score wynika też z tego, że strona ma porównawcze dane.
Zapytania z zerową widocznością (score 0-1):
- „Co powinien zawierać audyt SEO?” – score 0, citation rate 0%. Serwis ma dedykowaną stronę /audyt-seo/ i 5 artykułów w klastrze audytowym. Ale żaden z systemów AI nie cytuje tych stron. Powód: treść jest napisana w formacie marketingowym („Zamów profesjonalny audyt SEO”), nie w formacie answer-first („Audyt SEO powinien zawierać: analizę techniczną, analizę treści, analizę linków…”).
- „Co to jest audyt SEO?” – score 0,3. Tylko 1 z 150 uruchomień cytował serwis. Na to samo zapytanie Google AI Mode cytuje Wikipedię i portale branżowe – bo mają format definicyjny, który AI łatwo wyodrębnia.
- „Jak zrobić audyt SEO?” – score 1, citation rate 2%. Serwis ma artykuł z checklistą, ale odpowiedź jest zagrzebana pod wstępem marketingowym. AI go pomija.
Co to udowadnia?
To nas zaskoczyło najbardziej, bo nie widać tego w żadnym standardowym raporcie SEO: autorytet domeny nie wystarczy. Ten sam serwis, ten sam DR, ten sam profil linkowy – ale visibility score od 0 do 83 w zależności od tego, jak napisana jest strona docelowa. Podstrona szkoleń (answer-first, tabela cen, porównanie, FAQ) wygrywa. Podstrona audytu (marketingowy wstęp, brak definicji, brak checklisty) przegrywa.
I to jest chyba najważniejsza lekcja z tych 9095 uruchomień: AI nie ocenia Twojej domeny. AI ocenia konkretny fragment treści na konkretnej stronie pod kątem konkretnego zapytania. Możesz mieć najsilniejszą domenę w branży i zerową widoczność w AI – jeśli format treści nie pozwala systemowi wyodrębnić odpowiedzi.
Weryfikacja w czasie rzeczywistym – Perplexity odpytane przez DataForSEO
Żeby nie opierać się wyłącznie na danych historycznych z monitoringu, odpytaliśmy Perplexity w czasie pisania tego artykułu przez DataForSEO LLM Responses API. Dwa zapytania, ten sam serwis – dwa kompletnie różne wyniki.
Zapytanie: „Ile kosztuje szkolenie SEO w Polsce?”
Perplexity odpowiedział szczegółowo z 9 źródłami. Źródło numer 1 (oznaczone jako [1] w odpowiedzi) to strona monitorowanego serwisu – /szkolenie-seo/. AI bezpośrednio wyciągnął dane z tabeli cenowej: „od 4900 zł netto”, „szkolenia dedykowane z audytem od 5900 zł netto”. Dlaczego ta strona wygrała? Bo ma format answer-first: cennik jest w tabeli na górze strony, nie po 2000 słów wstępu. Fact density jest wysoka: 3 warianty cenowe, porównanie z konkurencją, FAQ. AI miał co cytować.

Zapytanie: „Co powinien zawierać profesjonalny audyt SEO?”
Perplexity odpowiedział równie szczegółowo – ale z 9 innych źródeł. Wśród cytowanych: cyberfolks.pl, verseo.pl, toponline.pl, maxroy.agency, netim.pl, jaaqob.pl. Monitorowany serwis? Nie pojawia się w żadnym z 9 cytowanych źródeł – mimo że ma dedykowaną stronę /audyt-seo/ i 5 artykułów o audytach. Powód: treść na tych stronach jest napisana w formacie „zamów audyt SEO” (konwersyjnym), nie „audyt SEO powinien zawierać X, Y, Z” (definicyjnym). AI nie znalazł fragmentu, który mógłby zacytować jako odpowiedź na pytanie.
To nie jest teoria – to dane z API odpytanego w czasie pisania tego artykułu. Ten sam serwis, ten sam autorytet, ten sam profil linkowy. Różnica: format i gęstość faktów na konkretnej stronie.
Dwa rodzaje cytowania: bezpośrednie i pośrednie
Przeskanowaliśmy strony cytowane przez Perplexity w odpowiedziach na nasze monitorowane prompty. Szukaliśmy jednego: czy zewnętrzne źródła (nie nasza własna strona) wspominają markę monitorowanego serwisu? Z 6 przeskanowanych domen cytowanych przez AI, dwie zawierały wzmiankę:
- seogroup.pl (ranking kursów SEO online) – wspomina markę w kontekście doświadczenia właściciela w branży SEO od 2010 roku. AI używa tego jako sygnału corroboration – niezależne źródło potwierdza istnienie i reputację marki.
- piotrskrzypek.pl (blog o nauce SEO) – wymienia blog monitorowanego serwisu na liście polecanych źródeł wiedzy SEO. Dwukrotna wzmianka.
Pozostałe 4 cytowane domeny (semcore.pl, whitepress.com, delante.pl, katsin.pl) – mimo że Perplexity je cytuje w odpowiedziach na te same prompty – nie wspominają monitorowanej marki w ogóle.
To dwa różne mechanizmy widoczności w AI. Cytowanie bezpośrednie: AI cytuje Twoją własną stronę jako źródło (np. semgence.pl/szkolenie-seo/ z cenami i formatami szkoleń). Cytowanie pośrednie: AI cytuje zewnętrzne źródło, które wspomina Twoją markę – i ta wzmianka wzmacnia zaufanie systemu do Twojej marki (patent US9785686B2, corroboration). Oba rodzaje się sumują. Dlatego budowanie obecności marki poza własną stroną (gościnne artykuły, rankingi branżowe, wypowiedzi eksperckie) bezpośrednio wpływa na częstotliwość cytowania przez AI – co potwierdzają też dane Ahrefs o korelacji 0,664 między wzmiankami a widocznością w AI.
Jakie typy treści AI cytuje najczęściej? Dane z 75 000 odpowiedzi
Badanie Wix AI Search Lab (marzec 2026) przeanalizowało 75 000 odpowiedzi AI z ponad milionem cytatów z trzech modeli: ChatGPT, Google AI Mode i Perplexity. Wynik: ponad połowa wszystkich cytatów AI (52%) pochodzi z trzech typów treści – listicles (rankingi/zestawienia), artykułów eksperckich i stron produktowych.
| Typ treści | Informational | Commercial | Transactional | Nav/local | Ogółem |
|---|---|---|---|---|---|
| Listicle (ranking) | 21,7% | 40,9% | 16,9% | 5,4% | 21,9% |
| Artykuł | 45,5% | 6,2% | 5,6% | 3,5% | 16,7% |
| Strona produktowa | 3,5% | 7,1% | 24,9% | 22,0% | 13,7% |
| Strona kategorii | 1,7% | 12,4% | 15,0% | 18,3% | 11,3% |
| Dyskusja (forum) | 4,4% | 11,4% | 6,7% | 8,0% | 7,5% |
| How-to guide | 9,2% | 3,9% | 7,4% | 3,5% | 6,2% |
| Homepage | 0,4% | 1,7% | 7,4% | 13,6% | 5,3% |
Co z tego wynika dla sklepów i serwisów usługowych?
- Artykuły eksperckie dominują w zapytaniach informacyjnych (45,5% cytatów). Jeśli piszesz artykuły answer-first z wysoką fact density – masz 2,7x większą szansę na cytowanie niż przy innych typach treści. To potwierdza naszą obserwację z monitoringu: artykuły z konkretnymi danymi (tabele cen, porównania, checklisty) wygrywają z treściami marketingowymi.
- Listicles (zestawienia, rankingi) dominują w zapytaniach komercyjnych (40,9%). Artykuły typu „Top 10 ekspresów do kawy” czy „Ranking kursów SEO” są cytowane 2x częściej niż przy innych intencjach. Ważne: 80,9% cytowanych listicles to zestawienia z zewnętrznych, neutralnych stron – nie autopromocyjne rankingi, w których marka stawia siebie na pierwszym miejscu.
- Strony produktowe i kategorii dominują w zapytaniach transakcyjnych (razem 40%). Jeśli Twój sklep ma dobrze zoptymalizowane karty produktowe z wysokim extractability score, AI będzie cytować je bezpośrednio w odpowiedziach na zapytania zakupowe.
- Perplexity cytuje fora i dyskusje 2x częściej niż inne modele (17% vs 7,5% średnia). Jeśli Twoja marka jest aktywna na Reddit, Quora czy branżowych forach – Perplexity to zauważy.
Podsumowanie – AI nie cytuje losowo, cytuje systemowo
Wybor źródeł do cytowania przez systemy AI nie jest losowy ani subiektywny. To algorytmiczny proces oparty na mierzalnych sygnałach: extractability treści (patent US10783156B1), gęstość faktow (US9672251B1), potwierdzenie przez niezależne źródła (US9785686B2), autorytet domeny i marki (US9031929B1), jasnosc encji (US9110852B1, US12547607B2) i information gain (US20140280011A1). Każdy z tych sygnałów możesz kontrolować i mierzyć.
Kluczowa różnica miedzy tradycyjnym SEO a optymalizacja pod AI: w SEO walczysz o pozycje na jedna fraze. W AI walczysz o pokrycie całego fan-outu zapytan – dziesiątek podzapytań, które AI generuje z jednego pytania użytkownika. Strona, która odpowiada na jedno pytanie, może zostac zacytowana raz. Strona, która odpowiada na 20 podzapytań z topical authority w danym temacie, będzie cytowana wielokrotnie.
Agencja SEO Semgence monitoruje widoczność klientow w systemach AI (ChatGPT, Perplexity, Gemini, Google AI Overviews) i optymalizuje treści pod katem cytowalnośći. Obejmuje to audyt extractability, analizę entity clarity, monitoring promptow i wdrozenie formatu answer-first. Sprawdź nasza oferte audytu widoczności w AI lub skontaktuj się z nami.
FAQ
Jak AI wybiera źródła do cytowania?
AI używa pipeline’u retrieval-augmented generation (RAG): rozkłada pytanie na podzapytańia, przeszukuje indeks webowy (Bing dla ChatGPT, Google dla Gemini), pobiera treść kandydatów, ocenia je pod katem extractability, fact density, autorytetu i spójności z innymi źródłami, a potem generuje odpowiedź z cytatami.
Dlaczego ChatGPT nie cytuje mojej strony?
Najczestsze przyczyny: robots.txt blokuje OAI-SearchBot (73% stron blokuje boty AI nieświadomie), strona nie jest zaindeksowana w Bing, treść nie jest w formacie answer-first, brak schema markup utrudnia rozpoznanie encji, lub strona laduje się dłużej niz 2 sekundy.
Jakie patenty Google opisują mechanizm wyboru źródeł?
Kluczowe patenty: US9672251B1 (fact density), US9785686B2 (corroboration – potwierdzanie faktow przez wiele źródeł), US10783156B1 (extractability), US9031929B1 (site quality i popyt na markę), US20250245255A1 (query fan-out i RAG retrieval).
Czym różni się GPTBot od OAI-SearchBot?
GPTBot crawluje strony na potrzeby treningu modeli AI – blokowanie go nie wpływa na cytowanie. OAI-SearchBot buduje indeks wyszukiwania ChatGPT Search – zablokowanie go oznacza, ze ChatGPT nigdy nie zacytuje Twojej strony. ChatGPT-User pobiera treść w czasie rzeczywistej rozmowy.







