Faceted navigation – czyli filtry po kolorze, rozmiarze, cenie i marce – to jednocześnie najważniejsza funkcja UX w sklepie internetowym i najczęstsza przyczyna problemów z crawl budgetem. Sklep z 1000 produktami i 4 filtrami po 10 opcji generuje ponad 10 000 kombinacji URL-i (10 x 10 x 10 x 10 = 10 000). Każda z nich to osobna strona, którą Googlebot musi zcrawlować – i w większości przypadków nie powinien. Bez kontroli faceted navigation sklep traci crawl budget na strony bez wartości SEO, a kluczowe karty produktowe i kategorie czekają tygodniami na indeksację. Podobnie jak filtry, niedostępne produkty potrafią zaśmiecać indeks, dlatego zobacz też out of stock SEO.
Czym jest faceted navigation i dlaczego stanowi problem SEO?
Faceted navigation to system filtrów pozwalający użytkownikom zawężać wyniki wyszukiwania w sklepie – po marce, kolorze, rozmiarze, cenie, materiale, ocenie i innych atrybutach. Z perspektywy UX to niezbędna funkcja: użytkownik, który szuka „butów do biegania damskich Nike w rozmiarze 39 do 300 zł”, nie chce przeglądać 2000 produktów. Filtry skracają ścieżkę do zakupu i mogą zwiększyć konwersję nawet o 20%. Przykład: sieć Elkjøp Nordic (elektronika, kraje skandynawskie) odnotowała 10% wyższy współczynnik konwersji wśród użytkowników korzystających z filtrów w porównaniu z ogólną konwersją sklepu. Po optymalizacji mobilnych filtrów bounce rate spadł o 4,19%, a konwersja wzrosła o 5,67%.
Problem pojawia się, gdy każda kombinacja filtrów generuje unikatowy URL. Adres /buty-do-biegania/?kolor=czarny&rozmiar=39&marka=nike&cena=do-300 to dla Google osobna strona – z treścią niemal identyczną jak /buty-do-biegania/?kolor=czarny&rozmiar=40&marka=nike. Katalog z 4 filtrami po 10 opcji tworzy matematycznie 10 000+ takich kombinacji (10^4). Przy 6 filtrach po 10 opcji to już milion URL-i (10^6).

Według oficjalnej dokumentacji Google, crawlowanie faceted URL-i „zwykle kosztuje strony duże ilości zasobów obliczeniowych ze względu na samą liczbę URL-i i operacji potrzebnych do renderowania tych stron”. Google wprost rekomenduje ograniczanie crawlowania tych adresów.
Jakie problemy SEO powoduje niekontrolowana faceted navigation?
Niekontrolowana faceted navigation wywołuje cztery problemy, które kumulują się i wzajemnie wzmacniają. Pierwszy to marnotrawstwo crawl budgetu – Googlebot spędza czas na stronach filtrowych zamiast na kartach produktowych i kategoriach, które powinny rankować. Case study agencji Ranks Digital Media pokazuje skalę problemu: w jednym ze sklepów Googlebot przeznaczał 65% crawl budgetu na warianty wyszukiwania wewnętrznego i faceted URL-i. Po naprawie crawl rate na stronach produktowych wzrósł o 40%, a czas indeksacji nowych produktów spadł z trzech tygodni do 48 godzin.
Drugi problem to duplikacja treści. Strona z filtrem ?kolor=czarny wyświetla te same produkty co strona z filtrem ?kolor=czarny&sort=cena. Google widzi dwie strony z identyczną treścią i musi zdecydować, która jest kanoniczna. Bez jasnych sygnałów (canonical, noindex) wyszukiwarka może wybrać złą wersję lub podzielić sygnały rankingowe między duplikaty.
Trzeci to rozwodnienie link equity. Linki wewnętrzne prowadzące do filtrowanych wariantów rozpraszają wartość, która powinna trafiać do głównych stron kategorii. Czwarty problem to index bloat – tysiące niskiej jakości stron filtrowych w indeksie obniżają ogólną jakość domeny w oczach algorytmu Google.
Skala problemu w liczbach: według danych z audytów 1200 sklepów (LOGEIX), 43% ruchu e-commerce pochodzi z wyszukiwania organicznego, ale 50% sklepów nie ma nawet schema Product na stronach produktowych, 55% ładuje się dłużej niż 3 sekundy, a 29% nie ma żadnych opisów produktów. Niekontrolowana faceted navigation pogłębia te problemy – dodaje do indeksu tysiące thin pages (stron filtrowych z minimalną treścią), co obniża ogólną jakość domeny w oczach algorytmu Google.
Jak sprawdzić, czy faceted navigation szkodzi Twojemu sklepowi?
Zacznij od prostego testu w Google: wpisz site:twojadomena.pl i sprawdź liczbę zaindeksowanych stron. Jeśli Google pokazuje 50 000 stron, a Twój sklep ma 3000 produktów i 200 kategorii – masz problem z index bloatem. Nadwyżka to prawdopodobnie warianty faceted navigation.
Następnie sprawdź Google Search Console. Przejdź do Ustawienia, potem Crawlowanie i Statystyki crawlowania. W sekcji „Według typu pliku” kliknij HTML – zobaczysz listę crawlowanych URL-i z datami. Jeśli adresy z parametrami filtrów (?kolor=, ?rozmiar=, ?sort=) dominują na liście, Googlebot marnuje crawl budget na faceted URL-i.
W raporcie „Strony” w GSC sprawdź sekcję „Wykryte, obecnie niezaindeksowane” (Discovered, currently not indexed). Jeśli znajdują się tam ważne strony produktowe lub kategorii, a jednocześnie tysiące filtrowych URL-i jest zaindeksowanych – crawl budget jest źle alokowany. Narzędzie Screaming Frog pozwala zcrawlować sklep i policzyć wszystkie warianty URL-i generowane przez filtry.
Dlaczego w Google Search Console widzisz tysiące „niezaindeksowanych” stron i dlaczego to dobrze?
Po wdrożeniu kontroli faceted navigation w raporcie Strony (Pages) w Google Search Console pojawi się duża liczba URL-i ze statusem „Zduplikowana, przesłany adres URL nie został wybrany jako kanoniczny” (Duplicate, submitted URL is not the selected canonical) lub „Wykryte, obecnie niezaindeksowane” (Discovered, currently not indexed). To nie jest błąd. To dowód, że kontrola działa prawidłowo.
Gdy ustawiasz canonical na stronie filtrowej wskazujący na główną kategorię, Google rozpoznaje duplikat i świadomie NIE indeksuje wersji filtrowej. W raporcie GSC ta strona pojawia się jako „nie wybrana jako kanoniczna” – co oznacza, że Google zaakceptował Twoją sugestię i skonsolidował sygnały na preferowanym URL-u. Analogicznie: strony z tagiem noindex pojawią się jako „Wykluczone przez tag noindex” – znowu, celowe i prawidłowe działanie.
Błędem byłoby odwrotnie: gdyby Google indeksował tysiące wariantów filtrowych, a główne strony kategorii traciły pozycje z powodu kanibalizacji. Dlatego wzrost liczby „niezaindeksowanych” stron w GSC po optymalizacji faceted navigation jest pozytywnym sygnałem. Ważne: regularnie sprawdzaj, czy wśród „niezaindeksowanych” nie znalazły się strony, które POWINNY być zaindeksowane (produkty, kategorie) – to byłby sygnał, że kontrola jest zbyt agresywna.
Praktyczna zasada: jeśli Twój sklep ma 3000 produktów i 200 kategorii, to w indeksie Google powinno być około 3000-4000 stron (produkty + kategorie + blog). Jeśli GSC pokazuje 15 000 zaindeksowanych i 40 000 „niezaindeksowanych” – faceted navigation jest pod kontrolą. Jeśli pokazuje 40 000 zaindeksowanych i 5000 „niezaindeksowanych” – filtry zalewają indeks i wymagają naprawy.
Jakie są metody kontrolowania faceted navigation?
Nie ma jednego uniwersalnego rozwiązania – skuteczna kontrola faceted navigation wymaga kombinacji kilku metod. Każda z nich ma swoje zalety i ograniczenia, dlatego trzeba dobrać je do specyfiki sklepu, platformy CMS i skali katalog.
Canonical tags – konsolidacja sygnałów rankingowych
Tag rel="canonical" wskazuje Google, która wersja strony jest preferowana. Wszystkie warianty filtrowe kategorii powinny mieć canonical wskazujący na główny URL kategorii bez parametrów. Na przykład: /buty-do-biegania/?kolor=czarny&rozmiar=39 powinno mieć canonical na /buty-do-biegania/. Google skonsoliduje sygnały rankingowe na jednym URL.
Ważne zastrzeżenie: canonical to sugestia, nie dyrektywa. Google może go zignorować. Co więcej, canonical nie rozwiązuje problemu crawl budgetu – Googlebot i tak musi zcrawlować stronę, żeby zobaczyć tag canonical. Dlatego canonical powinien być stosowany razem z innymi metodami.
Robots.txt – blokowanie crawlowania parametrów
Plik robots.txt pozwala zablokować crawlowanie konkretnych wzorców URL-i. Reguła Disallow: /*?sort= zablokuje wszystkie URL-e z parametrem sortowania. To skuteczna metoda oszczędzania crawl budgetu, ale ma istotne ograniczenie: robots.txt blokuje crawlowanie, nie indeksację. Jeśli Google zna URL z innego źródła (np. linku zewnętrznego), może go zaindeksować bez crawlowania – z pustym snippetem.
Meta robots noindex, follow – najlepsze z dwóch światów
Tag <meta name="robots" content="noindex, follow"> na stronach filtrowych mówi Google: „nie indeksuj tej strony, ale śledź linki na niej”. To oznacza, że strona filtrowa nie trafi do indeksu (bez duplikacji), ale linki do produktów na niej będą nadal przekazywać link equity. To optymalne rozwiązanie dla filtrów typu sortowanie, zakres cenowy i kombinacje wielu filtrów.
Wada: Google nadal crawluje te strony (żeby zobaczyć tag noindex), więc nie oszczędza to crawl budgetu tak jak robots.txt. Dlatego Search Engine Land rekomenduje łączenie noindex z innymi metodami – np. ograniczenie linków wewnętrznych do stron filtrowych.
AJAX i client-side filtering – filtrowanie bez nowych URL-i
Najbardziej radykalne rozwiązanie: filtry działają po stronie klienta (JavaScript/AJAX) i nie generują nowych URL-i w ogóle. Użytkownik klika „czarny” i lista produktów się aktualizuje, ale URL w przeglądarce nie zmienia się (lub zmienia się tylko fragment po #). Googlebot nie widzi żadnych dodatkowych stron do crawlowania.
To rozwiązanie idealnie chroni crawl budget, ale ma wadę: jeśli jakaś kombinacja filtrów ma realny potencjał SEO (np. „buty nike damskie” ma 5000 wyszukiwań miesięcznie), strona z tym filtrem nie będzie indeksowana. Dlatego AJAX sprawdza się najlepiej w połączeniu z selektywną indeksacją.
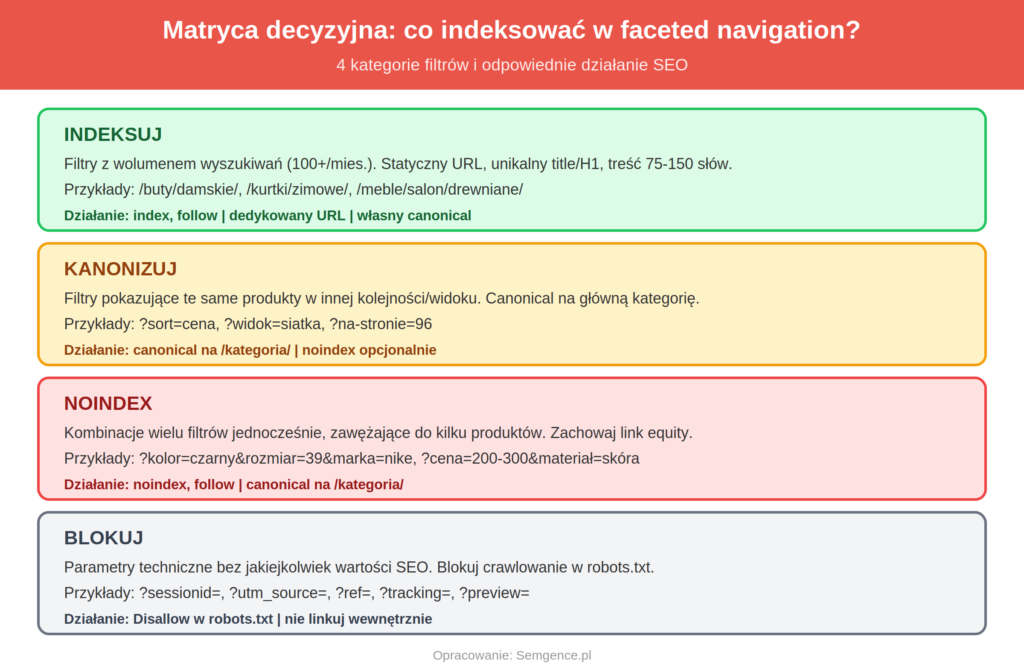
Jak zdecydować, które filtry indeksować, a które blokować?
To kluczowa decyzja strategiczna. Zasada jest prosta: indeksuj filtr tylko wtedy, gdy kombinacja ma realny wolumen wyszukiwań i unikatową treść. Wszystko inne blokuj. W praktyce oznacza to podział filtrów na cztery kategorie.
Pierwsza kategoria: filtry do indeksowania. To kombinacje z udowodnionym wolumenem wyszukiwań – np. /buty-do-biegania/damskie/ czy /kurtki/zimowe/. Te filtry powinny mieć dedykowane, czytelne URL-e (nie parametry), unikalny tag title i H1, oraz treść uzupełniającą (krótki opis kategorii). Sprawdź wolumen w Ahrefs lub Senuto przed podjęciem decyzji.
Druga: filtry do kanonizacji. Kombinacje, które pokazują te same produkty w innej kolejności lub z minimalną zmianą – np. sortowanie po cenie, wyświetlanie 24/48/96 produktów na stronie. Canonical na główny URL kategorii.
Trzecia: filtry do noindex. Kombinacje wielu filtrów jednocześnie (kolor + rozmiar + marka), które zawężają wyniki do kilku produktów. Noindex, follow – nie indeksuj, ale zachowaj przepływ link equity.
Czwarta: filtry do blokowania w robots.txt. Parametry techniczne bez żadnej wartości SEO – session ID, tracking codes, widok listy/siatki. Blokuj przed crawlowaniem.
Jak faceted navigation łączy się z query fan-out, encjami i architekturą treści?
Decyzja o tym, które filtry indeksować, a które blokować, nie powinna opierać się wyłącznie na wolumenie wyszukiwań. Wymaga zrozumienia, jak wyszukiwarki i systemy AI rozkładają zapytania użytkowników na podzapytania – to mechanizm znany jako query fan-out.
Gdy użytkownik wpisuje „buty do biegania”, Google (i systemy AI jak ChatGPT czy Perplexity) rozkładają to zapytanie na kilkanaście podzapytań: buty do biegania damskie, buty do biegania Nike, buty do biegania po asfalcie, buty do biegania do 300 zł, najlepsze buty do biegania na początek. Każde z tych podzapytań odpowiada potencjalnej stronie filtrowej w Twoim sklepie. Analiza query fan-out pokazuje, które kombinacje filtrów mają realny popyt – i to właśnie te kombinacje warto indeksować jako przyjazne URL-e.
Encje produktowe i kategorialne w kontekście filtrów
Każdy indeksowany URL z nawigacji fasetowej powinien budować jasność encji – jednoznacznie definiować, czym jest ta strona w kontekście grafu wiedzy Google. Strona /buty-do-biegania/damskie/nike/ powinna jasno komunikować trzy encje: kategoria (buty do biegania), atrybut (damskie), marka (Nike). Robimy to przez unikalny H1 zawierający te encje, schema markup Product z atrybutami brand/gender/category, i treść wprowadzającą opisującą relacje między tymi encjami.
Jeśli indeksujesz stronę filtrową BEZ jasnej definicji encji – bez unikalnego H1, bez schema, z szablonowym opisem „Wyniki dla: kolor czarny, rozmiar 39” – tworzysz thin page, która nie buduje topical authority i zamiast pomagać, osłabia domenę. Dlatego zasada brzmi: indeksuj filtr tylko wtedy, gdy jesteś w stanie nadać mu wyraźną tożsamość encyjną.
Faceted navigation jako element Semantic Content Network
W dobrze zaprojektowanym sklepie internetowym nawigacja fasetowa to nie odizolowany element techniczny – to część szerszej sieci semantycznej (Semantic Content Network, SCN) łączącej strony produktowe, kategorie, blog i treści poradnikowe. Indeksowane strony filtrowe powinny być wplecione w tę sieć: strona /buty-do-biegania/damskie/ linkuje do poradnika „Jak dobrać buty do biegania dla kobiet” na blogu, a poradnik linkuje z powrotem do strony filtrowej. To zamknięta pętla tematyczna budująca autorytet.
Bez tej integracji indeksowane strony filtrowe wiszą w próżni – nie mają kontekstu semantycznego, nie budują klastrów tematycznych i nie wzmacniają głównych stron kategorii. Zanim zdecydujesz się indeksować filtr, sprawdź: czy masz treść na blogu, która go wspiera? Czy istnieją cross-linki? Czy ten filtr wpisuje się w istniejącą architekturę hub&spoke (więcej o wpływie architektury informacji na crawl depth i odkrywalność treści)? Jeśli odpowiedź brzmi „nie” – filtr powinien zostać pod noindex/canonical, dopóki nie zbudujesz wokół niego kontekstu. Więcej o budowaniu sieci semantycznych opisujemy w kontekście audytu widoczności w AI.
Jak wygląda implementacja na popularnych platformach e-commerce?
- WooCommerce – faceted navigation z wtyczek (WooCommerce Product Filter, FacetWP, FLAVOR). Wyłącz generowanie URL-i dla kombinacji filtrów, ustaw canonical na kategorię, dodaj noindex do parametrów. W
functions.phpfiltrwoocommerce_get_catalog_ordering_argskontroluje parametry URL. - Shopify – wbudowana nawigacja domyślnie dodaje canonical do stron kolekcji z filtrami. Uwaga na customowe filtry z aplikacji (Boost Product Filter) – sprawdź czy dodaje noindex do wielopoziomowych kombinacji.
- Magento 2 – Layered Navigation domyślnie generuje URL-e z parametrami. Moduł Amasty Improved Layered Navigation oferuje zarządzanie canonical i noindex per filtr.
- Prestashop – moduł Faceted Search (ps_facetedsearch) ma opcję „Include filters in the URL” – wyłącz ją dla filtrów bez potencjału SEO.
Co zmienia AI w kontekście crawl budgetu e-commerce?
W 2026 roku crawl budget to nie tylko Googlebot. Według danych Cloudflare Radar, boty stanowią około 32% wszystkich requestów HTTP, a crawlery AI (GPTBot, ClaudeBot, PerplexityBot, Meta-ExternalAgent, Applebot) generują coraz większy ruch. Każdy niekontrolowany URL faceted navigation jest teraz crawlowany nie przez jednego bota, ale przez kilkanaście – Googlebot, Bingbot, GPTBot, ClaudeBot i inne.
To oznacza, że problem crawl budgetu się multiplikuje. Sklep, który nie kontroluje faceted navigation, oddaje zasoby serwera botom AI crawlującym tysiące wariantów filtrowych bez żadnej wartości. Rozwiązanie: zaktualizuj robots.txt o reguły dla botów AI. Zablokuj crawlowanie faceted URL-i przez GPTBot i ClaudeBot (boty treningowe), ale pozwól na crawlowanie przez OAI-SearchBot (bot odpowiedzialny za odpowiedzi ChatGPT Search) – ale tylko na głównych stronach kategorii, nie na wariantach filtrowych.
Jak mierzyć efekty optymalizacji faceted navigation?
Po wdrożeniu zmian monitoruj cztery metryki:
- Statystyki crawlowania (GSC > Ustawienia > Crawlowanie) – sprawdź czy Googlebot crawluje mniej stron filtrowych i więcej produktowych.
- Czas indeksacji nowych produktów – dodaj nowy produkt, zmierz ile dni zajmuje pojawienie się w indeksie (Inspekcja URL w GSC).
- Liczba zaindeksowanych stron (operator
site:w Google) – powinna spadać do realnej liczby wartościowych stron. - Ruch organiczny na kategoriach – powinien rosnąć w ciągu 4-8 tygodni od wdrożenia.
W case study Ranks Digital Media efekty były widoczne w ciągu trzech tygodni: crawl rate na stronach produktowych wzrósł o 40%, czas indeksacji spadł z 3 tygodni do 48 godzin, a ruch organiczny wzrósł o 22%. To pokazuje, że optymalizacja crawl budgetu daje mierzalne wyniki szybciej niż większość działań SEO.
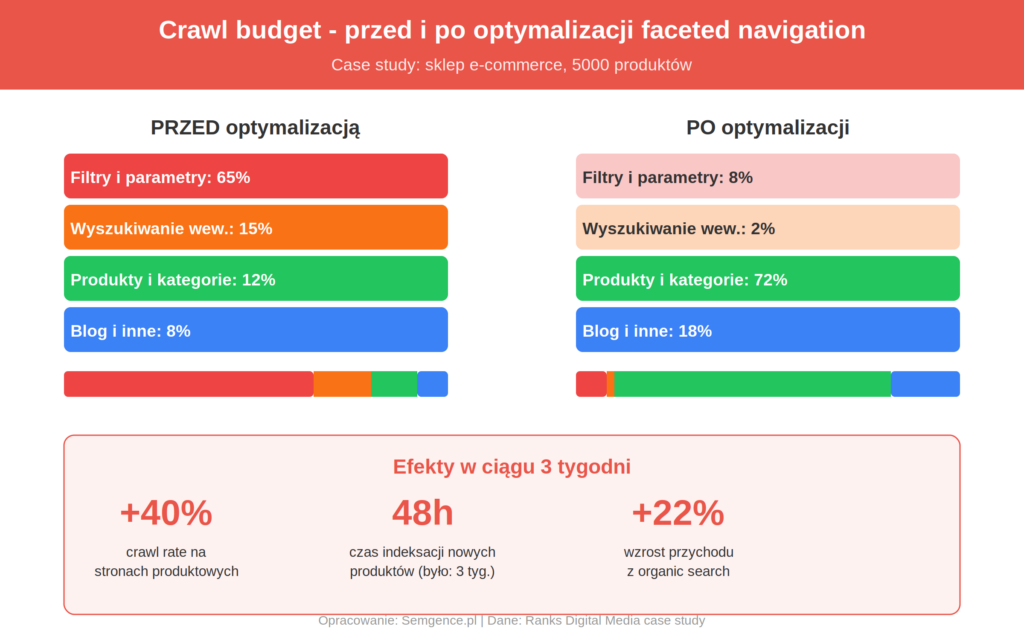
Jak wygląda prawidłowa struktura URL-i w sklepie z faceted navigation?
Kluczowa zasada: filtry z potencjałem SEO powinny generować statyczne, czytelne URL-e – nie parametry. Zamiast /buty/?marka=nike&plec=damskie lepiej: /buty/damskie/nike/. Taki URL jest czytelny dla użytkownika, zawiera frazy kluczowe i może rankować na „buty damskie nike”. Jednocześnie wielopoziomowe kombinacje (kolor + rozmiar + cena) powinny pozostać jako parametry z noindex lub AJAX.
Przykład prawidłowej architektury URL dla sklepu obuwniczego:
/buty-do-biegania/– główna kategoria (indeksowana, canonical na siebie)/buty-do-biegania/damskie/– podkategoria z wolumenem (indeksowana, własny title/H1)/buty-do-biegania/damskie/nike/– marka z wolumenem (indeksowana, jeśli >100 wyszukiwań/mies.)/buty-do-biegania/?kolor=czarny&rozmiar=39– kombinacja filtrów (noindex, follow, canonical na /buty-do-biegania/)/buty-do-biegania/?sort=cena-rosnaco– sortowanie (noindex, follow lub blokada w robots.txt)
Ta architektura pozwala indeksować kombinacje z realnym potencjałem SEO, jednocześnie chroniąc crawl budget przed tysiącami wariantów bez wartości. Każdy indeksowany URL powinien mieć unikalny tag title, H1 i – idealnie – 75-150 słów treści wprowadzającej nad listą produktów. Więcej o optymalizacji stron kategorii znajdziesz w naszym artykule o tym, jak pisać opisy kategorii w sklepie.
Czy warto przerabiać nawigację fasetową na przyjazne adresy URL i je pozycjonować?
Na pierwszy rzut oka pomysł brzmi sensownie: zamiast /buty/?kolor=czarny&rozmiar=39 tworzymy /buty/czarne/rozmiar-39/, optymalizujemy title i H1, dodajemy treść – i pozycjonujemy. Problem w tym, że ta strategia niesie realne ryzyko biznesowe i SEO, które w dłuższej perspektywie może kosztować więcej niż przynosi.
Kluczowe pytanie brzmi: ile kombinacji filtrów przerabiasz na przyjazne URL-e? Jeśli Twój sklep ma 200 kategorii i 10 filtrów (kolor, rozmiar, marka, materiał, cena, sezon, styl, płeć, ocena, dostępność) – to potencjalnie tysiące „przyjaznych” adresów do utworzenia, optymalizacji i utrzymania. Każdy z nich potrzebuje unikalnego title, H1, opisu i – idealnie – treści wprowadzającej. Pytanie: czy masz zasoby, żeby tworzyć i aktualizować unikalne treści na tysiącach stron filtrowych? Podejście programmatic SEO może tu pomóc, ale wymaga osobnej strategii. Jeśli nie – powstają thin pages z szablonowym contentem, które obniżają jakość domeny.
Ryzyko #1: duplikacja treści i kanibalizacja wewnętrzna
Strona /buty/damskie/nike/ i strona /buty/do-biegania/nike/ mogą wyświetlać te same produkty (buty Nike damskie do biegania). Google widzi dwie strony o bardzo podobnej treści targetujące zbliżone frazy kluczowe. Zamiast budować autorytet jednej silnej strony, rozpraszasz go na dwie słabe. To klasyczna kanibalizacja wewnętrzna – dwie strony z Twojego sklepu rywalizują ze sobą w wynikach Google, zamiast wspólnie budować pozycję.
Im więcej kombinacji filtrów przerobisz na przyjazne URL-e, tym większe ryzyko kanibalizacji. Przy 50 takich stronach problem jest zarządzalny. Przy 500 – staje się krytyczny. Przy 5000 – praktycznie niemożliwy do opanowania bez zaawansowanych narzędzi i stałego monitoringu.
Ryzyko #2: nagromadzenie URL-i w indeksie i zaburzenie crawl budgetu
Paradoksalnie, przerabianie filtrów na przyjazne URL-e i wpuszczanie ich do indeksacji może wywołać dokładnie ten sam problem, który miałeś z parametrami – tyle że teraz URL-e wyglądają ładnie. Zamiast 10 000 adresów z parametrami masz 10 000 „przyjaznych” URL-i, które nadal marnują crawl budget, tworzą duplikację i rozwadniają link equity. Forma URL-a się zmieniła, problem SEO pozostał ten sam.
W pierwszej fazie (1-3 miesiące po wdrożeniu) możesz zobaczyć korzyści: nowe strony filtrowe łapią pozycje na long tail frazy, ruch rośnie. Ale w dłuższej perspektywie (6-12 miesięcy) Google zaczyna dostrzegać skalę duplikacji, jakość domeny spada, a główne strony kategorii – te, które generują największy przychód – tracą pozycje. Efekt netto jest ujemny.
Kiedy przerabianie filtrów MA sens?
Strategia indeksowania przyjaznych URL-i z nawigacji fasetowej ma sens TYLKO gdy spełnione są trzy warunki jednocześnie:
- Udowodniony wolumen wyszukiwań – nie 10, ale setki lub tysiące miesięcznie. Sprawdź w Ahrefs lub narzędziach do keyword research.
- Unikatowy zestaw produktów – strona filtrowa wyświetla produkty, których nie pokrywa żadna inna strona w sklepie. Zero overlapa z innymi kategoriami.
- Możliwość utrzymania unikalnej treści – opis, poradnik zakupowy, porównanie. Nie szablon z nazwą filtra w title.
W praktyce oznacza to, że z tysięcy możliwych kombinacji filtrów warto przerobić na przyjazne URL-e i indeksować najwyżej 20-50. Reszta powinna pozostać pod kontrolą canonical/noindex/AJAX. Lepiej mieć 30 doskonale zoptymalizowanych stron podkategorii niż 3000 thin pages z przyjaznym URL-em ale zerową wartością dla użytkownika.
Checklist – kontrola faceted navigation w 10 krokach
Poniższy checklist obejmuje kluczowe działania do wdrożenia w każdym sklepie internetowym z faceted navigation. Kolejność jest istotna – zacznij od audytu, potem podejmij decyzje strategiczne, a na końcu wdrażaj techniczne rozwiązania.
- Sprawdź liczbę zaindeksowanych stron:
site:twojadomena.plw Google. Porównaj z realną liczbą produktów + kategorii. - Przeanalizuj Crawl Stats w Google Search Console – jaki procent crawli trafia na URL-e z parametrami?
- Skategoryzuj filtry: które mają realny wolumen wyszukiwań (Ahrefs/Senuto), a które nie?
- Filtry z wolumenem: utwórz dedykowane, statyczne URL-e (nie parametry) z unikalnym title/H1.
- Filtry bez wolumenu (kolor, rozmiar, materiał): ustaw noindex, follow + canonical na główną kategorię.
- Sortowanie i paginacja: zablokuj w robots.txt lub ustaw noindex.
- Rozważ AJAX/client-side filtering dla kombinacji wielofiltrowych.
- Zaktualizuj robots.txt o reguły blokujące parametry techniczne i boty AI.
- Sprawdź tagi canonical na stronach filtrowych – czy wskazują na główną kategorię?
- Monitoruj efekty: crawl stats (GSC), indeksacja (site:), ruch organiczny (GA4) przez 4-8 tygodni.
Jakie są najczęstsze błędy przy obsłudze faceted navigation?
- Brak jakiejkolwiek kontroli – sklep generuje tysiące URL-i z parametrami, nie ma canonicali, nie ma noindex, robots.txt nie blokuje niczego. Domyślne ustawienie większości platform „out of the box”. Według analiz Ranks Digital Media, nawet 65% crawl budgetu trafia na URL-e filtrowe.
- Robots.txt BEZ noindex – robots.txt blokuje crawlowanie, ale nie indeksację. Link zewnętrzny do filtrowego URL-a = Google indeksuje go z pustym snippetem. Search Engine Land rekomenduje łączenie obu metod.
- Indeksowanie WSZYSTKICH filtrów „na wszelki wypadek” – prowadzi do index bloatu. Lepiej 50 dobrze zoptymalizowanych stron kategorii niż 5000 thin pages z filtrami.
- Niespójna implementacja – canonical wskazuje na jedną stronę, sitemap na inną, linkowanie na trzecią. Google otrzymuje sprzeczne sygnały. Spójność canonical + sitemap + linkowania = fundament. Więcej w artykule o optymalizacji sklepu pod SEO.
Agencja SEO Semgence przeprowadza audyty faceted navigation w ramach audytu SEO sklepu internetowego. Analizujemy log files serwera, crawl stats z GSC i strukturę URL-i, żeby zidentyfikować, ile crawl budgetu marnuje się na filtry i jak to naprawić. Sprawdź kompletny framework skalowania sprzedaży przez SEO lub naszą ofertę pozycjonowania sklepów internetowych. Jeśli Twój sklep działa na WooCommerce, przeczytaj jak pozycjonować sklep na WooCommerce lub skontaktuj się z nami.
Podsumowanie – faceted navigation to problem do rozwiązania, nie do ignorowania
Faceted navigation to problem, który dotyczy każdego sklepu internetowego z więcej niż kilkudziesięcioma produktami. Ignorowanie go prowadzi do marnotrawstwa crawl budgetu, duplikacji treści i index bloatu – trzech czynników, które systematycznie obniżają widoczność organiczną sklepu. W 2026 roku problem się pogłębia, bo obok Googlebota faceted URL-e crawlują też boty AI: GPTBot, ClaudeBot, PerplexityBot i inne.
Dobra wiadomość: rozwiązanie jest techniczne i mierzalne. Kombinacja canonical tags, noindex/follow, robots.txt i selektywnej indeksacji pozwala odzyskać crawl budget, skonsolidować sygnały rankingowe i skupić uwagę Google na stronach, które generują przychód – kategoriach i kartach produktowych. Efekty widać szybko: w opisanym case study crawl rate na stronach produktowych wzrósł o 40% w ciągu trzech tygodni.
Jeśli nie wiesz, czy faceted navigation szkodzi Twojemu sklepowi, zacznij od dwóch prostych sprawdzeń: site:twojadomena.pl w Google (czy liczba stron jest realna?) i Statystyki crawlowania w Google Search Console (co crawluje Googlebot?). Te dwa kroki zajmą 5 minut i pokażą, czy masz problem wymagający interwencji.
FAQ
Czym jest faceted navigation w sklepie internetowym?
Faceted navigation to system filtrów w sklepie online pozwalający użytkownikom zawężać listę produktów po atrybutach: marka, kolor, rozmiar, cena, materiał, ocena. Każda kombinacja filtrów może generować osobny URL, co przy dużych katalogach tworzy tysiące lub miliony stron – i stanowi główne wyzwanie SEO w e-commerce.
Czy faceted navigation szkodzi SEO?
Niekontrolowana faceted navigation szkodzi SEO na trzy sposoby: marnuje crawl budget (Googlebot crawluje tysiące stron filtrowych zamiast produktowych), tworzy duplikację treści (podobne strony z minimalnymi różnicami) i powoduje index bloat (tysiące niskiej jakości stron w indeksie). Kontrolowana faceted navigation – z canonical, noindex i AJAX – nie szkodzi SEO.
Jak naprawić problemy z faceted navigation?
Cztery metody: 1) Canonical tags – wskaż Google preferowaną wersję strony, 2) Noindex, follow – nie indeksuj filtrów, ale zachowaj link equity, 3) Robots.txt – zablokuj crawlowanie parametrów bez wartości SEO, 4) AJAX/client-side filtering – filtry działają bez generowania nowych URL-i. Najskuteczniejsza jest kombinacja tych metod dopasowana do specyfiki sklepu.
Jak sprawdzić crawl budget w Google Search Console?
W GSC przejdź do Ustawienia, Crawlowanie, Statystyki crawlowania. Sprawdź sekcję 'Według typu pliku’ i kliknij HTML – zobaczysz listę crawlowanych URL-i. Jeśli dominują adresy z parametrami filtrów (?kolor=, ?sort=, ?rozmiar=), Googlebot marnuje crawl budget na faceted navigation zamiast na wartościowe strony produktowe i kategorie.







