Google AI Mode i AI Overviews nie odpowiadają na jedno pytanie — rozbijają je na 5–20 subzapytań, przeszukują web równolegle i składają odpowiedź z wielu źródeł. To oznacza, że audyt oparty na jednej frazie jest dziś zbyt płytki. Wygrywa ten, kto pokrywa pełną mapę subpromptów: mechanizm, cenę, porównania, ryzyka, scenariusze użycia i pytania poboczne. Ten artykuł pokazuje, jak to działa technicznie, skąd to wiemy (dwa patenty Google), jak testować pokrycie i jak przełożyć fan-out na brief contentowy.
Dlaczego jeden keyword już nie wystarczy?
Przez lata audyt SEO działał według prostego modelu: wybierz frazę, sprawdź pozycję, zoptymalizuj stronę. Fraza „audyt SEO” miała jedną stronę docelową, jeden title tag i jedną intencję do obsłużenia. Jeśli ktoś pytał „ile kosztuje audyt SEO” — to było osobne zapytanie, osobna strona, osobny ranking.
Ten model się skończył. Nie dlatego, że SEO umarło (nie umarło), ale dlatego, że sposób, w jaki Google interpretuje i realizuje zapytanie, zmienił się strukturalnie.
Od marca 2025 roku Google oficjalnie opisuje technikę query fan-out jako mechanizm napędzający zarówno AI Overviews, jak i AI Mode. W dokumentacji Google Search Central czytamy wprost, że oba systemy mogą uruchamiać wiele powiązanych wyszukiwań równocześnie — po różnych subtematach i źródłach danych — a następnie składać wynik w jedną spójną odpowiedź. To nie jest eksperyment. AI Mode działa na Gemini 3 Flash globalnie od grudnia 2025. Deep Search, zaawansowana wersja fan-out, potrafi uruchomić setki wyszukiwań na raz. Więcej o naszym podejściu do pozycjonowania w AI.
Konsekwencja jest prosta: jeśli twoja strona odpowiada tylko na jeden aspekt pytania, może nie pojawić się w odpowiedzi AI, która składa się z wielu aspektów zarazem. Audyt musi patrzeć szerzej — na mapę subpromptów, nie na pojedynczą frazę.
Co to jest query fan-out i jak działa w praktyce?
Query fan-out to technika rozszerzania zapytania, w której system AI bierze jedno pytanie użytkownika i rozbija je na wiele subzapytań (subqueries). Każde subzapytanie eksploruje inny aspekt problemu. Wyniki ze wszystkich subzapytań trafiają do modelu, który syntetyzuje je w jedną odpowiedź — z linkami do różnych źródeł pokrywających różne fragmenty tematu. Google rozszerzył tę logikę nawet na wyszukiwanie wizualne — „visual search fan-out” analizuje szczegóły obrazu i generuje subzapytania na podstawie tego, co widzi.
To nie jest lista synonimów. Fan-out to rozgałęzienie problemu na różne ścieżki badawcze.
Jak to wygląda od środka
Załóżmy, że użytkownik wpisuje w Google AI Mode pytanie:
„Czy audyt SEO ma sens dla sklepu internetowego?”
System nie szuka jednej strony, która odpowiada na to pytanie. Generuje subzapytania pokrywające różne aspekty:
| Aspekt | Przykładowe subzapytanie |
|---|---|
| Mechanizm | co to jest audyt SEO |
| Zakres | co powinien zawierać audyt SEO |
| Koszt | ile kosztuje audyt SEO |
| Porównanie | darmowy vs płatny audyt SEO |
| Scenariusz użycia (use case) | audyt SEO dla e-commerce |
| Ryzyko | najczęstsze błędy SEO w sklepie |
| Decyzja | jak wybrać wykonawcę audytu SEO |
| Efekt (outcome) | czy audyt SEO zwiększa sprzedaż |
| Pytanie FAQ | kiedy robić audyt SEO |

Każde z tych subzapytań uruchamia osobne wyszukiwanie. Wyniki trafiają do modelu Gemini, który:
- Wybiera najistotniejsze fragmenty z wielu stron,
- Składa je w jedną, ustrukturyzowaną odpowiedź,
- Dobiera linki źródłowe do każdego aspektu osobno.
W efekcie odpowiedź AI Mode może cytować 15–20 różnych stron — każda pokrywająca inny kawałek tematu.
Skąd wiemy, że Google to robi?
Google potwierdza fan-out w trzech miejscach a przy tym:
- Dokumentacja Google Search Central — strona „AI Features and Your Website” mówi wprost, że AI Overviews i AI Mode mogą używać techniki query fan-out, uruchamiając wiele powiązanych wyszukiwań po subtematach i źródłach danych.
- Blog Google — wpis o AI Mode z marca 2025 opisuje fan-out jako mechanizm uruchamiający wiele powiązanych wyszukiwań równocześnie po subtematach i wielu źródłach danych. Wpis o Deep Search z Google I/O 2025 opisuje rozszerzoną wersję, która może uruchamiać setki wyszukiwań na raz.
- Patenty Google — dwa kluczowe patenty opisują mechanikę tego procesu od strony technicznej (więcej o nich w osobnej sekcji poniżej).
Co mówią dane o skali query fan-out?
Fan-out to nie teoretyczna możliwość systemu, który czasem się uruchamia. To mechanizm działający przy niemal połowie zapytań. W maju 2026 roku DataForSEO opublikowało badanie obejmujące 100 000 rzeczywistych promptów użytkowników ChatGPT i ponad 100 000 wygenerowanych fan-out queries. Wyniki potwierdzają to, co obserwujemy w praktyce audytowej – ale dodają do tego twarde liczby.
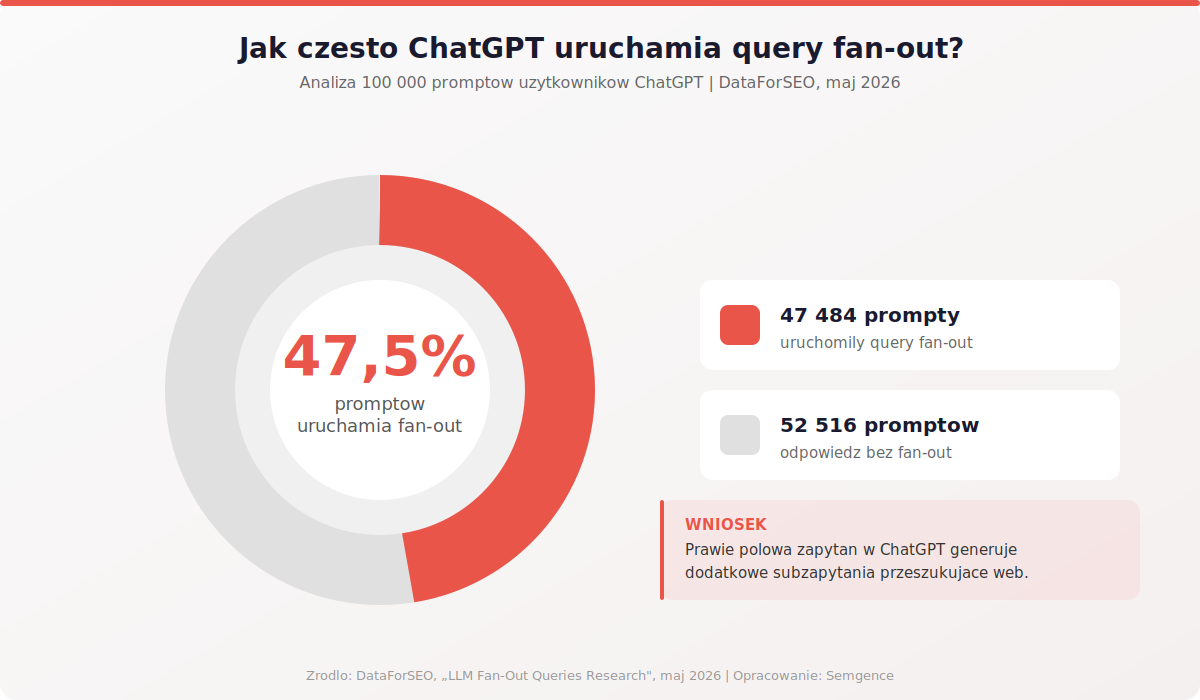
47,5% promptów uruchamia fan-out
Spośród 100 000 zbadanych promptów, 47 484 (czyli 47,5%) wywołało generowanie dodatkowych subzapytań przeszukujących web. To oznacza, że prawie co drugi prompt, jaki użytkownik wpisuje w ChatGPT, nie jest obsługiwany bezpośrednio z wiedzy modelu. Zamiast tego LLM generuje subzapytania, odpala wyszukiwanie i dopiero z wyników składa odpowiedź.
Dla SEO ta liczba zmienia perspektywę. Jeśli twoja treść jest widoczna tylko dla oryginalnego promptu, a nie dla subzapytań, które AI generuje w tle, tracisz szansę na pojawienie się w prawie połowie odpowiedzi. Identyfikacja i pokrycie fan-out queries staje się tak samo ważne jak optymalizacja pod główne słowo kluczowe.
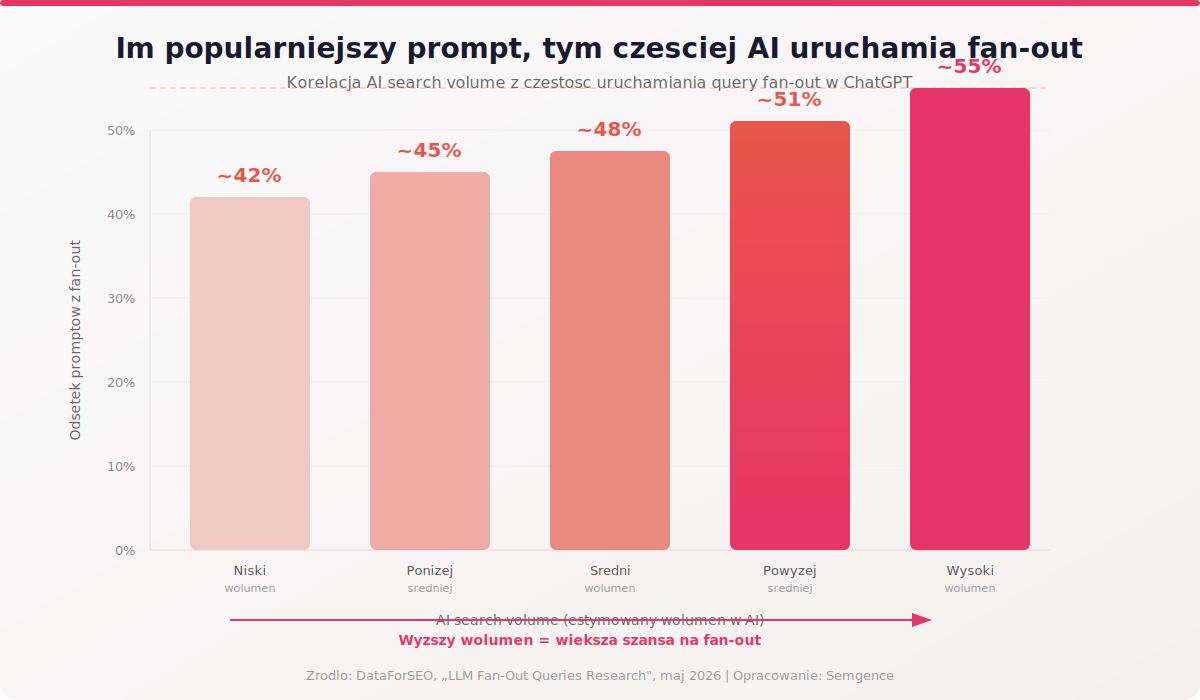
Wyższy wolumen = więcej fan-out
Badanie DataForSEO pokazało wyraźną korelację między popularnością promptu (mierzoną metryką AI search volume) a częstością uruchamiania fan-out. Prompty o niskim wolumenie generują fan-out w ok. 42% przypadków. Prompty o wysokim AI search volume robią to w 51-55% przypadków.
To logiczne. Popularne tematy (technologia, podróże, zdrowie, finanse) wymagają analizy z wielu perspektyw, porównań i aktualnych danych. Model nie może odpowiedzieć z pamięci – musi przeszukać web. Dla strategii contentowej wniosek jest prosty: im bardziej konkurencyjny temat, tym większe prawdopodobieństwo, że AI będzie aktywnie szukać źródeł przez fan-out. A to oznacza, że pokrycie subzapytań na takich tematach daje największy zwrot.
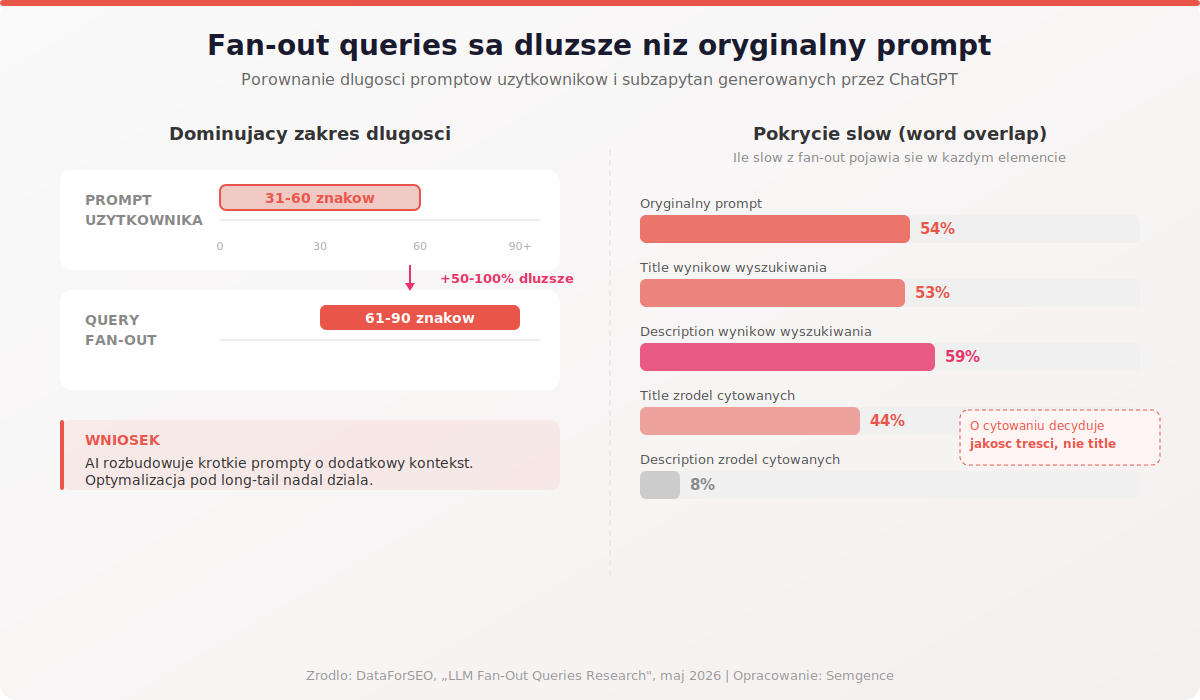
Fan-out queries są dłuższe niż prompt użytkownika
Porównanie długości promptów i wygenerowanych subzapytań ujawniło kolejny wzorzec. Większość promptów mieści się w zakresie 31-60 znaków. Natomiast fan-out queries są konsekwentnie dłuższe – dominuje przedział 61-90 znaków. ChatGPT nie kopiuje oryginalnego pytania. Rozbudowuje je o dodatkowy kontekst, ograniczenia i precyzyjniejsze sformułowania.
To potwierdza coś, co w audytach widoczności w AI obserwujemy od dawna: optymalizacja pod long-tail nadal działa. Treści pokrywające konkretne, rozbudowane zapytania mają przewagę, bo lepiej trafiają w formę subzapytań, które AI generuje w tle. Krótki, ogólnikowy content pod head-term nie wystarczy – potrzebna jest głębokość i precyzja.
Title i description decydują o odkryciu, jakość treści – o cytowaniu
Jednym z najciekawszych wyników badania jest analiza pokrycia słów (word overlap) między fan-out queries a różnymi elementami wyników wyszukiwania. Subzapytania dzielą 54% słów z oryginalnym promptem, 53% z tytułami wyników wyszukiwania i aż 59% z meta description wyników. To oznacza, że title tag i meta description nadal mają bezpośredni wpływ na to, czy strona zostanie odnaleziona przez AI.
Ale jest druga strona medalu. Pokrycie słów z description źródeł faktycznie cytowanych w odpowiedzi wynosi zaledwie 8%. Innymi słowy: dobrze zoptymalizowany title i description pomogą ci zostać odkrytym przez fan-out, ale o tym, czy AI cię zacytuje, decyduje jakość i użyteczność treści na stronie – nie dopasowanie meta tagów. To wzmacnia nasze podejście w audycie SEO: metadata otwiera drzwi, content zamyka deal.
Pełne wyniki badania, w tym rozkłady długości, analizy per branża i metodologia, są dostępne w raporcie DataForSEO „LLM Fan-Out Queries Research”.
Dlaczego query fan-out zmienia sposób myślenia o audycie?
Stary model: zorientowany na słowo kluczowe (keyword-centric)
W klasycznym audycie kluczowe pytanie brzmiało: „Czy mam stronę na tę frazę?”
Sprawdzałeś pozycję, title tag, H1, gęstość słów kluczowych. Jeśli strona rankowała na „audyt SEO” — zadanie było zrobione. Warianty frazy (audit SEO, audyt seo strony, seo audyt) traktowałeś jako dodatkowe cele, ale logika była ta sama: jedna fraza → jedna strona → jeden ranking.
Nowy model: zorientowany na pokrycie (coverage-centric)
W świecie query fan-out kluczowe pytanie brzmi: „Czy pokrywam subprompty, które AI może wygenerować wokół tego pytania?”
To zmiana z optymalizacji pod keyword na optymalizację pod kompletność odpowiedzi. Audyt musi teraz oceniać:
- Zakres odpowiedzi — czy twój content adresuje wiele aspektów pytania, nie tylko jeden?
- Różne intencje — czy pokrywasz intencję informacyjną (co to jest), decyzyjną (jak wybrać), kosztową (ile kosztuje) i porównawczą (A vs B)?
- Treści wspierające (supporting content) — czy istnieją osobne strony lub sekcje na tematy poboczne, które mogą być trafione przez subzapytania?
- FAQ — czy najczęstsze pytania są pokryte i łatwe do wyekstrahowania przez model?
- Linkowanie wewnętrzne — czy strony powiązane tematycznie są ze sobą połączone, tworząc spójną sieć topiczną?
- Kontekst i dowody — czy content zawiera dane, przykłady, case studies — sygnały, które AI wykorzystuje do oceny wiarygodności źródła?
Nie chodzi o to, żeby jedna strona odpowiadała na 20 pytań. Chodzi o to, żeby architektura treści — zestaw stron, sekcji, FAQ i linków — pokrywała logiczne ścieżki eksploracji, które system AI może wygenerować. Jak pisze Google w przewodniku „Succeeding in AI Search”: kluczem jest unikatowy, wartościowy content, który odpowiada na realne potrzeby użytkowników — a AI search experience pozwala im zadawać dłuższe, bardziej złożone pytania niż kiedykolwiek.
Jakie typy subpromptów AI generuje wokół jednego pytania?
Fan-out to nie lista wariantów jednej frazy. To zbiór pytań o różnych funkcjach, z których każde prowadzi do innego typu treści w architekturze serwisu.
Na podstawie analizy dokumentacji Google, patentów i praktyki operacyjnej wyróżniamy następujące klasy subpromptów:
| Typ subpromptu | Co bada | Przykład (seed: „audyt SEO”) | Gdzie trafia w architekturze |
|---|---|---|---|
| Mechanism | Na czym polega, jak działa | „co to jest audyt SEO” | Strona definicyjna / lead sekcji |
| Scope | Co obejmuje, co zawiera | „co powinien zawierać audyt SEO” | Sekcja H2 lub osobny URL |
| Price | Ile kosztuje, cennik | „ile kosztuje audyt SEO” | Sekcja H2 z tabelą cenową |
| Comparison | Alternatywy, A vs B | „darmowy vs płatny audyt SEO” | Tabela porównawcza / osobny URL |
| Risk | Błędy, pułapki, czego unikać | „najczęstsze błędy SEO w sklepie” | Sekcja H2 lub treści wspierające |
| Use case | Dla kogo, kiedy, branże | „audyt SEO dla e-commerce” | Wariant branżowy / case study |
| Local | Warianty geograficzne | „audyt SEO Warszawa” | Strona lokalna |
| Decision | Jak wybrać, kryteria | „jak wybrać agencję do audytu SEO” | Strona decyzyjna / poradnik |
| Outcome | Korzyści, efekty, ROI | „czy audyt SEO zwiększa sprzedaż” | Case study / sekcja z danymi |
| Question (FAQ/PAA) | Konkretne pytania użytkowników | „kiedy robić audyt SEO” | FAQ / sekcja Q&A |
Dlaczego ta klasyfikacja ma znaczenie
Każdy typ subpromptu prowadzi do innego rodzaju treści. Jeśli twoja strona pokrywa tylko mechanism (co to jest audyt SEO) i scope (co zawiera), a pomija price, comparison i risk — system AI skompletuje odpowiedź z innych źródeł, które te aspekty pokrywają.
Warto patrzeć na to przez pryzmat Semantic Content Network (SCN): pillar page pokrywa mechanism i scope, treści wspierające (supporting content) pokrywają price, comparison, risk i use case, a FAQ agreguje pytania (questions). Linkowanie wewnętrzne łączy te elementy w spójny graf wiedzy, który AI może eksplorować.
Jakie patenty Google tłumaczą logikę fan-out?
W obiegu SEO często mówi się o „patencie fan-out” — ale tak naprawdę chodzi o dwa różne patenty, które opisują dwa różne etapy tego samego procesu.
Patent 1: US11663201B2 — generowanie wariantów zapytania
Patent złożony w 2018 roku, przyznany w maju 2023, zatytułowany „Generating query variants using a trained generative model.” Opisuje system, w którym model generatywny produkuje wiele wariantów jednego zapytania. Patent definiuje osiem typów wariantów: equivalent (alternatywne sformułowania), follow-up (logiczne pytania wynikowe), generalization (szersze wersje), specification (węższe wersje), canonicalization (znormalizowane formy), language translation (tłumaczenia), entailment (pytania logicznie wynikające) i clarification (pytania doprecyzowujące). Każdy wariant jest osobno przesyłany do systemu wyszukiwania, a wyniki są syntetyzowane w jedną odpowiedź. Szczegółową analizę mechaniki tych wariantów opisał DEJAN w artykule „Google’s Query Fan-Out System: A Technical Overview”. Ten patent tłumaczy mechanizm, czyli jak system generuje subzapytania.
Warto zaznaczyć: patent nie jest potwierdzeniem, że AI Mode = ten patent w stosunku 1:1. Google nigdy nie potwierdza bezpośredniego zastosowania wynalazków z patentów. Ale logika rozszerzania eksploracji wokół jednego pytania, opisana w patencie, jest zbieżna z tym, co Google opisuje w dokumentacji o fan-out.
Patent 2: US12158907B1 — Thematic Search
Patent złożony w grudniu 2024, zatytułowany „Thematic Search.” Opisuje system, który organizuje wyniki wyszukiwania w kategorie tematyczne (themes) i generuje skróty (summaries) dla każdej grupy. Zapytanie może prowadzić do wielu sub-tematów (sub-themes), a każdy sub-temat może generować kolejne pod-pod-tematy. Patent opisuje, jak użytkownik może eksplorować temat coraz głębiej — a system na każdym poziomie pobiera nowe wyniki i organizuje je w kolejne grupy tematyczne. Związki tego patentu z fan-out szczegółowo opisał Roger Montti z Search Engine Journal. Ten patent tłumaczy prezentację, czyli jak system organizuje wyniki subzapytań w strukturę tematyczną.
Co to oznacza razem
Patent US11663201B2 opisuje silnik generowania — jak jedno pytanie zamienia się w wiele wariantów. Patent US12158907B1 opisuje warstwę organizacyjną — jak wyniki wielu wyszukiwań są grupowane w tematy i sub-tematy. Razem tworzą obraz systemu, który: generuje subzapytania → uruchamia wiele wyszukiwań → organizuje wyniki w strukturę tematyczną → prezentuje syntezę użytkownikowi.
Tego właśnie doświadczamy w AI Mode: jedno pytanie, wiele subzapytań, tematycznie zorganizowana odpowiedź z linkami do wielu źródeł.
Dlaczego pojedyncze zapytanie do ChatGPT nie wystarczy?
Wielu specjalistów SEO i content strategistów testuje pokrycie tematu jednym promptem: wpisują pytanie do ChatGPT, czytają odpowiedź i uznają, że temat jest ogarnięty. To niebezpieczny skrót.
Jeden prompt = jedna ścieżka odpowiedzi
Gdy wpiszesz „czy audyt SEO ma sens dla sklepu internetowego?” do ChatGPT, dostaniesz jedną odpowiedź. Prawdopodobnie pokryje ona definicję audytu i kilka argumentów za. Ale jeden prompt nie pokaże ci:
- ile kosztuje audyt SEO (aspekt cenowy),
- czym różni się darmowy od płatnego (porównanie),
- jakie błędy najczęściej znajduje audyt w e-commerce (ryzyko branżowe),
- jak wybrać wykonawcę (aspekt decyzyjny),
- jakie są lokalne warianty usługi (local),
- co mówią firmy, które zrobiły audyt — jakie efekty osiągnęły (efekty).
Fan-out = wiele ścieżek eksploracji
Google AI Mode nie zadaje jednego pytania. Rozbija je na subzapytania i eksploruje każdy aspekt osobno. Jak opisuje blog Google o Gemini 3 w Search: dzięki zaawansowanemu rozumieniu intencji, fan-out potrafi teraz odnajdywać treści, które wcześniej mogłyby zostać pominięte. Wynik: odpowiedź pokrywa mechanizm, zakres, cenę, porównania, ryzyka, scenariusze użycia i pytania FAQ — wszystko naraz, z różnych źródeł.
Jeśli twoja analiza tematu bazuje na jednym prompcie, widzisz jedną ścieżkę. Fan-out widzi ich dziesięć albo dwadzieścia. Różnica między tymi podejściami to różnica między audytem powierzchownym a audytem kompletnym.
Jak testować pokrycie subpromptów w audycie?
To jest najbardziej operacyjna sekcja artykułu. Poniżej framework, który stosujemy w Semgence do testowania pokrycia (coverage) fan-out.
Krok 1: wybierz seed query
Zacznij od pytania o realnej wartości biznesowej — frazy, na którą zależy ci najbardziej. Najlepiej takiej, która łączy intencję informacyjną z decyzyjną, np. „czy audyt SEO ma sens dla sklepu” albo „najlepszy CRM dla B2B SaaS.”
Krok 2: zbierz subqueries z wielu źródeł
Nie polegaj na jednym narzędziu. Każde źródło widzi inny wycinek zapytań:
- People Also Ask (Google) — pytania, które Google wiąże z twoim seed query w klasycznych SERPach
- AlsoAsked — drzewo pytań PAA, pogrupowane hierarchicznie
- Senuto — analiza pytań i fraz powiązanych na rynku polskim
- Ahrefs Keywords Explorer — matching terms, related terms, questions
- DataForSEO — dane z Google AI Mode i AI Overviews, w tym cytowane domeny i strony
- Heurystyki własne — subzapytania generowane przez model AI z promptem odwzorowującym logikę fan-out (np. nasz
query_fanout_orchestrator)
Krok 3: oznacz subzapytania aspektami
Każde zebrane subzapytanie przypisz do jednej z klas: mechanism, scope, price, comparison, risk, use case, local, decision, outcome, question. To daje ci mapę aspektów — widzisz, które aspekty tematu są pokryte przez dane z wielu źródeł, a które mają luki.
Krok 4: sklej warianty w query families
Cena / koszt / cennik / ile kosztuje — to jedna rodzina. Co to jest / na czym polega / jak działa — to rodzina mechanism. Nie traktuj każdego wariantu jako osobnego świata. Deduplikacja redukuje szum i pozwala skupić się na realnych lukach, a nie na wariantach leksykalnych tego samego pytania.
Krok 5: oceń pokrycie
Dla każdego aspektu sprawdź, czy jest pokryty przez:
- osobny URL — dedykowana strona na temat,
- sekcję H2 — fragment dłuższego artykułu,
- FAQ — pytanie i odpowiedź w sekcji Q&A,
- treści wspierające — artykuł wspierający, blog post, case study,
- linkowanie wewnętrzne — link z pillar page do treści wspierających i z powrotem.
Jeśli aspekt nie jest pokryty przez żaden z tych elementów, masz lukę treściową (content gap), którą AI może wypełnić treścią konkurencji.
Krok 6: oceń różnorodność źródeł (source diversity)
Sygnał z wielu źródeł jest silniejszy niż sygnał z jednego. Jeśli pytanie „ile kosztuje audyt SEO” pojawia się w PAA, Senuto i Ahrefs przy czym — to mocny sygnał realnego zapotrzebowania użytkowników. Jeśli pojawia się tylko w jednym narzędziu — jest słabsze i może być artefaktem danych lub po prostu pomyłką.
Różnorodność źródeł działa jak system głosowania: im więcej niezależnych źródeł potwierdza istnienie subzapytania, tym większe prawdopodobieństwo, że system AI wygeneruje je w procesie fan-out.
Jakie narzędzia wspierają query fan-out?
W Semgence zbudowaliśmy pipeline narzędziowy, który operacjonalizuje logikę query fan-out. Poniżej opis kluczowych komponentów — co przyjmują na wejściu i co dają na wyjściu.

query_fanout_orchestrator
Wejście: seed query (jedno pytanie bazowe) + opcjonalnie kontekst branżowy (e-commerce, B2B, usługi lokalne).
Co robi: Rozkłada pytanie na subzapytania w oparciu o 10 klas aspektów (mechanism, scope, price, comparison, risk, use case, local, decision, outcome, question). Generuje warianty, klasyfikuje je, deduplikuje rodziny zapytań.
Wyjście: Mapa subzapytań pogrupowana aspektami. Każde subzapytanie ma przypisany typ, rodzinę i priorytet.
query_fanout_content_activation
Wejście: Wynik z orchestratora (mapa subzapytań).
Co robi: Przekształca mapę subzapytań na plan wdrożeniowy: które subzapytania powinny mieć osobny URL, które powinny być sekcją H2, które FAQ, a które treści wspierające.
Wyjście: Plan contentowy z podziałem na sekcje główne, FAQ, treści wspierające i lukę treściową. Gotowy do włożenia do briefu.
query_fanout_brief_builder
Wejście: Plan z content activation + dane z GSC (Google Search Console) i GA4 (Google Analytics 4).
Co robi: Buduje gotowy brief contentowy z nagłówkami H2/H3, sugestią FAQ, rekomendacją internal linking i priorytetami treści opartymi na danych o ruchu i konwersjach.
Wyjście: Brief w formacie markdown, gotowy do przekazania autorowi lub zespołowi content.
Dane z DataForSEO, Senuto i Ahrefs
Wejście: Seed query, domena docelowa, kraj.
Co dostarczają: Pytania PAA, frazy powiązane, wolumeny wyszukiwań, pozycje konkurencji, dane o cytowaniach w AI Overviews (DataForSEO). Te dane zasilają orchestrator i activation jako zewnętrzne źródła sygnałów.
Jak to łączy się z audytem AI visibility
Wynik pokrycia (coverage) fan-out trafia do dashboardu AI Monitor (audyt widoczności w AI) w Metabase, gdzie porównujemy:
- które subzapytania nasza domena pokrywa,
- które pokrywa konkurencja,
- jak wygląda pokrycie w rozbiciu na wymiary (aspekty),
- czy widoczność w AI Overviews/AI Mode koreluje z pokrycie subzapytań.
O tym, jak monitorować zachowania AI w kontekście SEO, pisaliśmy w artykule o monitoringu promptów w AI Search.
Jak wykorzystać query fan-out przy budowie briefu contentowego?
Query fan-out nie kończy się na analizie. Powinien zasilać brief contentowy — i to w sposób strukturalny, nie jako „lista 20 pytań do jednego artykułu.”
Co fan-out zmienia w briefie
Nagłówki H2/H3 — zamiast wymyślać nagłówki, wyprowadź je z aspektów fan-out. Jeśli subzapytania wskazują na silne zainteresowanie ceną, porównaniami i ryzykami — te aspekty powinny mieć dedykowane H2.
FAQ — subzapytania z klasy „question” to gotowe kandydatki na FAQ. Ale nie wrzucaj ich wszystkich do jednej strony. FAQ powinno adresować pytania ściśle powiązane z tematem pillar page.
Supporting content (treści wspierające) — subzapytania z klas „use case”, „comparison” i „risk” często wymagają osobnych artykułów. Porównanie „A vs B” to z reguły osobna strona, nie sekcja w artykule definicyjnym.
Kolejność sekcji — dane o wolumenie i różnorodność źródeł (source diversity) pokazują, które aspekty są najważniejsze. Te z najwyższym popytem powinny być wyżej w strukturze strony.
Linkowanie wewnętrzne — brief powinien wskazywać, które istniejące strony powinny linkować do nowego contentu (i odwrotnie). Fan-out daje ci naturalne sugestie anchor textów: jeśli subzapytanie brzmi „audyt SEO dla e-commerce”, a taki artykuł już istnieje — link jest oczywisty.
Decyzja URL vs sekcja — nie każdy aspekt potrzebuje osobnej strony. Mechanism i scope mogą być sekcjami na pillar page. Price i comparison mogą być osobnymi URL-ami. Decision i efekty mogą być częścią case study. Fan-out + dane o wolumenie pomagają podjąć tę decyzję.
Nie zapominamy o BLUF-ie.
Czego nie robić
Nie wrzucaj 20 subzapytań do jednego artykułu. To nie jest cel fan-out. Celem jest sensowna architektura odpowiedzi: pillar page + treści wspierające + FAQ + linkowanie — a nie megaartykuł, który próbuje odpowiedzieć na wszystko.
Jakie są najczęstsze błędy w myśleniu o query fan-out?
1. Fan-out to nie lista synonimów. „Audyt SEO”, „audit SEO”, „seo audyt” — to warianty leksykalne, nie fan-out. Fan-out to pytania o różne aspekty tego samego problemu: cenę, ryzyko, porównania, scenariusze użycia.
2. Fan-out to nie rozszerzanie słów kluczowych (keyword expansion). Narzędzia do badania słów kluczowych (keyword research) dają ci warianty frazy. Fan-out daje ci mapę intencji. Różnica: rozszerzanie słów kluczowych odpowiada na pytanie „jak ludzie piszą to samo?”, fan-out odpowiada na pytanie „o co jeszcze ludzie pytają w kontekście tego tematu?”
3. Brak deduplikacji rodzin pytań. „Ile kosztuje audyt SEO”, „cena audytu SEO”, „cennik audytu SEO” — to jedna rodzina (price). Traktowanie każdego wariantu jako osobnego celu prowadzi do chaosu w architekturze treści i kanibalizacji.
4. Wrzucanie wszystkiego do jednego tekstu. 20 subzapytań ≠ 20 sekcji w jednym artykule. Część wymaga osobnych URL-i, część to FAQ, część to treści wspierające. Megaartykuł nie jest odpowiedzią na fan-out.
5. Ignorowanie różnorodności źródeł. Subzapytanie, które pojawia się w PAA, Senuto i Ahrefs, jest silniejszym sygnałem niż takie, które pojawia się tylko w jednym narzędziu. Bez analizy różnorodność źródeł traktujesz wszystkie subzapytania jednakowo — a nie są.
6. Zbyt silne poleganie na jednym prompcie. Jeden prompt do ChatGPT daje jedną odpowiedź. System fan-out generuje 5–20 subzapytań i eksploruje każde osobno. Testowanie pokrycia jednym promptem to jak testowanie widoczności jednym keywordem.
7. Ignorowanie aspektów. Bez klasyfikacji subzapytań (mechanism, price, risk..) nie wiesz, czy masz lukę treściową. Możesz mieć 50 subzapytań i nie widzieć, że wszystkie dotyczą mechanism i scope — a brakuje ci price i comparison.
Co powinien zawierać audyt pod AI search?
Poniżej checklista elementów, które audyt treści powinien oceniać, jeśli bierze pod uwagę query fan-out i logikę AI search.
Mapa subpromptów:
- Seed query zidentyfikowane
- Subzapytania zebrane z minimum 3 źródeł (PAA, narzędzie keyword, heurystyka AI)
- Subzapytania sklasyfikowane według aspektów (mechanism, scope, price, comparison, risk, use case, local, decision, outcome, question)
Rodziny zapytań (query families):
- Warianty leksykalne zdeduplikowane do rodzin
- Każda rodzina ma przypisany aspekt
Pokrycie aspektów (facet coverage):
- Dla każdego aspektu: sprawdzony status pokrycia (osobny URL / sekcja H2 / FAQ / treści wspierające / brak)
- Luki treściowe (content gap) zidentyfikowane
Różnorodność źródeł (source diversity):
- Dla każdego subzapytania: ile niezależnych źródeł je potwierdza
- Priorytetyzacja na podstawie wskaźnika różnorodności źródeł
Gotowość FAQ:
- Pytania z klasy „question” pokryte w FAQ
- FAQ oznaczone schema.org FAQPage (jeśli dotyczy)
- Odpowiedzi wystarczająco konkretne, żeby AI mógł je wyekstrahować
Gotowość treści wspierających:
- Artykuły wspierające istnieją dla kluczowych aspektów:
- Supporting content linkuje do i z pillar page
Gotowość linkowania wewnętrznego:
- Pillar page linkuje do treści wspierające per aspekt
- Supporting content linkuje zwrotnie do pillar page
- Anchory opisują intencję (nie „kliknij tutaj”, lecz „ile kosztuje audyt SEO”)
Dowody i konkrety:
- Content zawiera dane, statystyki, case studies
- Źródła danych wskazane i datowane
- Przykłady specyficzne dla branży/use case
Jak wygląda analiza query fan-out w praktyce?
- Ten artykuł gdy był analizowany w trakcie poprawek:

Powyższa tabela pokazuje wynik audytu tego artykułu (który czytasz) — sprawdzamy, czy tekst o query fan-out sam pokrywa aspekty, które definiuje. Artykuł adresuje 8 z 10 aspektów: mechanizm (definicja i diagram), zakres (checklista audytu), porównanie (stary vs nowy model), ryzyko (7 najczęstszych błędów), scenariusze użycia (e-commerce, CRM B2B) i decyzję (framework 6 kroków). Dwa aspekty pozostają niepokryte: cena (brak informacji o kosztach audytu) i efekt (brak konkretnych danych o wynikach wdrożenia fan-out). Aspekt lokalny nie dotyczy tego tematu.
- analiza frazy „kolczyki”

Drugi przykład dotyczy frazy „kolczyki” — typowej kategorii e-commerce. Seed query przepuszczone przez query_fanout_orchestrator wygenerowało 7 klastrów i 27 subzapytań po deduplikacji. Dane z Senuto potwierdziły realne wolumeny: „ile kosztuje kolczyk w pępku” (1 900 wyszukiwań/mies.), „czym czyścimy srebro” (2 900). Kluczowy wniosek: sklep z samym listingiem produktów przegrywa widoczność w AI Mode, bo nie pokrywa aspektów wyboru, pielęgnacji, ryzyk ani porównania materiałów. Rozwiązanie to architektura treści: strona kategorii + artykuł o pielęgnacji + FAQ + porównanie materiałów + linkowanie wewnętrzne. Pełna analiza dostępna w pliku PDF powyżej. Do waszej oceny czy to dobrze czy źle ale do briefu contentowego wsad się nadaje.
Plik do pobrania z analizą tylko dla słowa „kolczyki”: https://www.semgence.pl/wp-content/uploads/2026/04/kolczyki-quety-fan-out.pdf
Dlaczego audytujesz mapę pytań, a nie pojedynczą frazę?
Query fan-out to nie ciekawostka technologiczna. To zmiana w sposobie, w jaki Google interpretuje intencję użytkownika — od pojedynczego zapytania do wielowymiarowej eksploracji tematu.
Jeśli audytujesz tylko jedną frazę, audytujesz zbyt płytko. Jeśli twój brief contenowy nie uwzględnia subpromptów, tworzysz treść, która pokrywa jeden aspekt pytania — a AI Mode odpowiada na dziesięć.
Wygrywa ten, kto pokrywa logiczne ścieżki odpowiedzi: mechanizm, zakres, cenę, porównania, ryzyka, scenariusze użycia i pytania poboczne. Nie na jednej stronie — ale w spójnej architekturze treści: pillar page + treści wspierające + FAQ + linkowanie wewnętrzne.
To nie jest rewolucja. To ewolucja audytu — od modelu zorientowanego na słowo kluczowe do modelu zorientowanego na pokrycie. I wymaga narzędzi, które tę mapę subpromptów potrafią zbudować, sklasyfikować i przełożyć na plan treści.
Jeśli chcesz zobaczyć, jak z wyniku query fan-out zbudować gotowy brief contentowy — krok po kroku, na realnym przykładzie — napisz do nas lub sprawdź naszą ofertę konsultacji SEO.
Semgence wykorzystuje query fan-out w procesie audytu AI Search, rozbijając główne frazy klienta na subprzempty i mapując pokrycie treści.
FAQ
Co to jest query fan-out?
Query fan-out to mechanizm stosowany przez systemy AI (Google AI Overviews, ChatGPT, Perplexity), w którym jedno pytanie użytkownika jest rozbijane na kilkanaście lub kilkadziesiąt podzapytań. AI wyszukuje odpowiedzi na każde podzapytanie osobno, a potem syntetyzuje jedną odpowiedź z wielu źródeł. Oznacza to, że jedna strona nie musi odpowiadać na wszystko – musi odpowiadać na konkretne podzapytania lepiej niż konkurencja.
Jak query fan-out zmienia SEO?
Zamiast optymalizować jedną stronę pod jedno słowo kluczowe, trzeba budować klastry treści pokrywające cały ekosystem pytań wokół tematu. Audyt SEO pod AI search to nie analiza jednej frazy, ale mapowanie subpromptów (podzapytań), które AI generuje wokół danego tematu.
Jak sprawdzić, jakie subprompty AI generuje dla mojego tematu?
Trzy metody: 1) Wpisz pytanie w ChatGPT/Perplexity i przeanalizuj, na jakie aspekty AI odpowiada. 2) Użyj Google Suggest i People Also Ask dla wariantów zapytania. 3) Narzędzia SEO (Ahrefs, Senuto) do analizy powiązanych fraz. Porównaj pokrycie tych subpromptów z treścią na Twojej stronie.
Ile subpromptów generuje AI dla jednego pytania?
Zależy od złożoności tematu. Proste pytania faktograficzne: 3-5 subpromptów. Pytania porównawcze (’co lepsze X vs Y’): 8-15 subpromptów. Pytania eksperckie (’jak zrobić audyt SEO’): 15-30+ subpromptów obejmujących definicje, kroki, narzędzia, koszty, błędy i alternatywy.
![Co to jest i ile kosztuje inbound marketing? Przykłady [TOP 7]](https://www.semgence.pl/wp-content/uploads/2024/05/inbound-marketing-przyklady.png.webp)




