Topical authority jest jednym z najczęściej dyskutowanych konceptów w SEO, ale prawie nikt nie mówi o tym, jak go faktycznie zmierzyć. Większość artykułów (w tym nasz własny tekst o topical authority) wyjaśnia, czym jest autorytet tematyczny i dlaczego ma znaczenie. Ale brakuje odpowiedzi na pytanie praktyczne: skąd wiem, czy mój serwis faktycznie ma topical authority, czy go rozmywa, i gdzie dokładnie leży problem?
W tym artykule pokażę metodologię pomiaru, którą stosujemy w Semgence – opartą na embeddingach treści, mapie semantycznej serwisu i nałożeniu danych z Google Search Console. To podejście, które zamienia abstrakcyjny koncept w mierzalne wskaźniki i konkretne decyzje.
Dlaczego klasyczne narzędzia SEO nie mierzą topical authority?
Dlatego, że operują na poziomie pojedynczych URL-i i fraz kluczowych. Screaming Frog pokaże status code, canonical i word count. Ahrefs pokaże pozycje i backlinki. Google Search Console pokaże kliknięcia i wyświetlenia. Każde z tych narzędzi odpowiada na ważne pytania, ale żadne z nich nie odpowiada na pytanie kluczowe: jak treści w serwisie układają się wobec siebie semantycznie i czy ta struktura wspiera cele biznesowe?
Można mieć serwis, w którym 99% ruchu organicznego generują poradniki blogowe, a strony usługowe – te, które faktycznie przynoszą leady i przychód – są niewidoczne w Google. Klasyczny raport z GSC pokaże, że serwis ma ruch. Ale nie pokaże, że cały ten ruch ląduje na treściach top-of-funnel, a strony bottom-of-funnel nie mają ani widoczności, ani linków wewnętrznych, ani kontekstu tematycznego.
Żeby to zobaczyć, trzeba nałożyć na siebie trzy warstwy:
- co serwis faktycznie publikuje (warstwa treści),
- jak Google i użytkownicy widzą serwis (warstwa popytu),
- które strony mają wartość biznesową (warstwa priorytetów).
Dopiero połączenie tych trzech perspektyw daje obraz, na podstawie którego można podejmować decyzje strategiczne. Pisaliśmy o praktycznej stronie budowania topical authority w dobie AI – ten artykuł uzupełnia tamten o warstwę pomiarową.
Na czym polega pomiar topical authority za pomocą embeddingów?
Najskuteczniejsze podejście do pomiaru opiera się na embeddingach – wektorowych reprezentacjach semantycznych treści. Embedding to matematyczny opis tego, „o czym jest strona”, zapisany jako wektor wielowymiarowy. Dzięki embeddingom można policzyć, jak blisko siebie tematycznie znajdują się dwie strony, nawet jeśli nie używają tych samych słów kluczowych.
Proces wygląda następująco.
Dla każdej strony w serwisie budujemy tekst reprezentatywny, składający się z title, H1, meta description, wybranych H2 i słów z URL-a. Ten tekst zamieniamy na embedding za pomocą modelu językowego. Potem liczymy średni wektor wszystkich embeddingów w serwisie – to jest semantyczne centrum serwisu, tzw. site center.
Następnie dla każdej strony mierzymy odległość od tego centrum (cosine distance). Strony blisko centrum są spójne z głównym tematem serwisu. Strony daleko od centrum to outlierzy – treści poboczne, niszowe albo przypadkowe.
Warto podkreślić: embeddingi nie zastępują analizy słów kluczowych. One ją uzupełniają o wymiar, którego same słowa kluczowe nie mają – kontekst semantyczny. Dwie strony mogą nie dzielić ani jednego słowa kluczowego, a mimo to być blisko siebie w przestrzeni embeddingów, bo mówią o powiązanych koncepcjach. I odwrotnie – strony z tym samym słowem kluczowym mogą być daleko od siebie, bo traktują temat z zupełnie różnych perspektyw (np. „audyt SEO” jako usługa vs. „audyt SEO” jako poradnik jak go zrobić samodzielnie).
To jest powód, dla którego podejście oparte na embeddingach daje lepszy obraz topical authority niż podejście oparte wyłącznie na keyword overlap. Semantyka jest szersza niż leksyka. To samo podejście semantyczne stosujemy w pozycjonowaniu w AI, gdzie zrozumienie embeddingów jest kluczowe dla widoczności w odpowiedziach modeli językowych.

Czym jest site center i co mówią distance bands?
Site center to średni wektor semantyczny wszystkich stron w serwisie. Można o nim myśleć jak o „tematycznym środku ciężkości” – punkt, wokół którego skupiają się główne tematy serwisu. Na mapie jest oznaczony gwiazdą.
Wokół centrum wyznaczamy strefy dystansu (distance bands), które porządkują strony w cztery pierścienie:
- RDZEŃ – strony najbliżej centrum, tematycznie najbardziej spójne z głównym profilem serwisu,
- FOKUS – strony w orbicie głównych tematów, nadal dobrze powiązane z centrum,
- ROZSZERZENIE – strony tematycznie dalsze, ale wciąż w zasięgu serwisu,
- PERYFERIE – outlierzy, strony najdalej od centrum semantycznego.
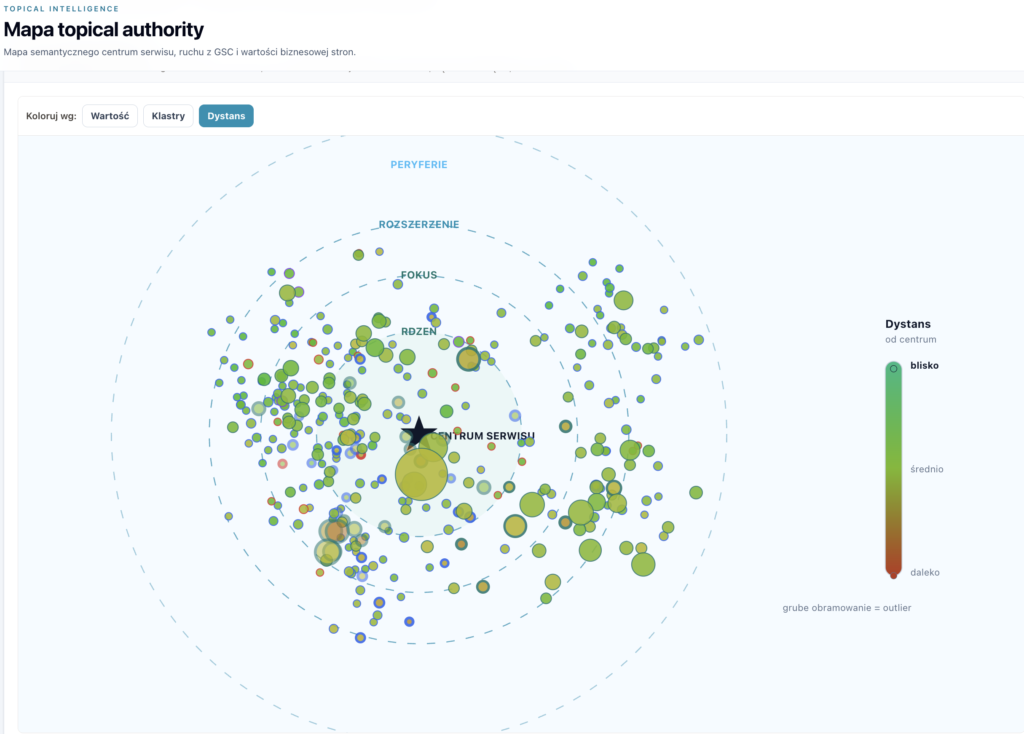
Na mapie w Topical Authority Intelligence każda strona pojawia się jako punkt. Położenie wynika z projekcji embeddingu na płaszczyznę 2D. Rozmiar bąbelka odpowiada kliknięciom z GSC – im większy punkt, tym więcej ruchu. Kolory oznaczają wartość biznesową strony lub przynależność do klastra.
To nie znaczy, że strony na peryferiach są automatycznie złe. Ale jeśli money page – strona usługowa, produktowa, ofertowa – jest daleko od centrum, to sygnał, że serwis zbudował autorytet tematyczny wokół czegoś innego niż to, co chce sprzedawać. I to jest jeden z najczęstszych problemów, jakie widzimy w audytach SEO.
Semgence zbudowało panel Topical Authority Intelligence, który automatyzuje cały pipeline: od crawla Screaming Frog, przez liczenie embeddingów, po nakładanie danych z Google Search Console i wizualizację na interaktywnej mapie.
Jak porównać to, co serwis publikuje, z tym, co widzi Google?
To rozróżnienie jest kluczowe i w naszym narzędziu nazywamy je perspektywą supply-side vs. demand-side.
Perspektywa supply-side odpowiada na pytanie: co serwis faktycznie publikuje? Liczymy ją na embeddingach treści. Patrzymy na to, jak strony układają się semantycznie, jakie tworzą klastry, co jest rdzeniem, a co outlierem. Supply-side mówi o intencji wydawcy.
Perspektywa demand-side odpowiada na pytanie: jak Google i użytkownicy widzą serwis? Liczymy ją na danych z Google Search Console – zapytaniach, kliknięciach, wyświetleniach. Demand-side mówi o intencji rynku.
Obie perspektywy mają swoje metryki. SiteFocus mierzy, jak skupiony tematycznie jest serwis (1.0 = idealnie spójny, 0.0 = totalnie rozproszony). SiteRadius mierzy rozrzut tematyczny. Liczymy je osobno dla treści (supply) i popytu (demand).
Najciekawsze są rozjazdy między tymi perspektywami.
Przykład pierwszy: wysoki SiteFocus z GSC, niski SiteFocus z embeddingów. Ruch jest skupiony tematycznie, ale serwis ma dużo treści pobocznych, które nie rankują. To sygnał do pruningu – usuwania lub konsolidacji treści, które nie wspierają głównego tematu.
Przykład drugi: niski SiteFocus z GSC, wysoki SiteFocus z embeddingów. Treść jest spójna, ale Google widzi serwis przez szeroki long-tail. Serwis łapie wiele pobocznych intencji, które warto uporządkować w hubach.
Przykład trzeci: money pages daleko od centrum, a poradniki edukacyjne w centrum z prawie całym ruchem. Top-of-funnel content wykonuje całą pracę SEO, ale strony sprzedażowe są niewidoczne. Strategia powinna skupić się na dolinkowaniu i rozbudowie money pages.
Na mapie te rozjazdy widać dosłownie. Strona usługowa, która powinna być fundamentem serwisu, pojawia się jako mały, ciemny punkt na obrzeżach – daleko od klastra poradników, który dominuje centrum. To jest moment, w którym dane zaczynają opowiadać historię, a nie tylko wypełniać tabelkę.
Narzędzie Topical Authority Intelligence w Semgence mierzy oba wskaźniki – SiteFocus i SiteRadius – osobno dla treści (supply) i popytu (demand), a potem zestawia je w jednym widoku analitycznym (zakładka Wnioski), żeby rozjazdy były widoczne od razu. Widok zawiera też priorytety, diagnostykę klastrów, listę outlierów i porównanie runów w czasie.

Co oznaczają buckety Keep, Grow, Relocate i Prune?
Każda strona w analizie trafia do jednego z czterech bucketów strategicznych. To warstwa decyzyjna – zamienia surowe dane w konkretne rekomendacje.
Keep – wysoki ruch i wysoka wartość biznesowa. Te strony pracują. Są strategiczne. Trzeba je utrzymywać, pilnować pozycji, aktualności treści i linkowania. To filary serwisu.
Grow – wysoka wartość biznesowa, ale niski ruch. To najważniejszy bucket szans. Money page, która powinna generować leady, ale nie ma wystarczającej widoczności w Google. Kandydat do rozbudowy treści, linkowania wewnętrznego i lepszego dopasowania pod zapytania. W większości audytów to właśnie bucket Grow zawiera strony, na których warto skupić 80% pracy.
Relocate – wysoki ruch, ale niska wartość biznesowa. Strona generuje widoczność, ale niekoniecznie wspiera biznes. Może rozpraszać topical authority. Ale zamiast ją usuwać, warto wykorzystać jej ruch – dodać linki kontekstowe do stron Grow, sekcje „co dalej”, CTA do usług.
Prune – niski ruch i niska wartość. Kandydat do aktualizacji, konsolidacji z silniejszym URL-em, noindex albo usunięcia. Szczegółową metodologię oceny treści opisujemy w ramach audytu treści. Strony Prune rozmywają topical authority, bo dodają szum semantyczny do serwisu bez zwrotu w postaci ruchu czy konwersji.

Jak Link Planner wykorzystuje embeddingi i dane GSC do rekomendacji linkowania?
Standardowe podejście do linkowania wewnętrznego polega na ręcznym szukaniu powiązań między stronami. Link Planner v2 w Topical Authority Intelligence automatyzuje ten proces, łącząc kilka warstw danych.
Rekomendacja linkowania nie mówi już tylko „te strony są blisko w embeddingach”. Odpowiada na pytanie: czy warto dodać link z tej strony do tej strony, bo są blisko semantycznie, mają podobną intencję z GSC i mogą przenieść ruch lub autorytet na ważny target?
Scoring bierze pod uwagę sześć składników:
- wartość biznesową targetu (czy target jest money page),
- kliknięcia source’a (czy source ma ruch do przekazania),
- wartość biznesową source’a,
- bliskość semantyczną (cosine distance między embeddingami),
- query overlap (czy source i target mają wspólne zapytania z GSC),
- intent match (czy intencje zapytań się pokrywają, nawet jeśli same zapytania są inne).
Każda rekomendacja ma uzasadnienie w języku naturalnym, np.: „Bliski sąsiad semantyczny (0.224); źródło Grow; target Grow o wartości 90; wspólne query: audyt linków, audyt linków zwrotnych.”
Shared queries to szczególnie wartościowy sygnał. Jeśli dwie strony rankują na te same lub bardzo podobne zapytania, link między nimi wzmacnia sygnał tematyczny dla obu. Google widzi, że serwis pokrywa temat z wielu stron i łączy je w spójną strukturę. To mechanizm, który bezpośrednio wspiera topical authority na poziomie klastra.
Dodatkowo Link Planner filtruje techniczne URL-e (paginacje, tagi, kategorie, feedy, attachment, wp-json), żeby rekomendacje dotyczyły wyłącznie stron, na których linkowanie ma sens. Każdy link dostaje status – do wdrożenia, wdrożony, odrzucony – co pozwala traktować listę jako backlog operacyjny.
Cyrus Shepard z Zyppy podkreślał w swoich badaniach, że linki wewnętrzne kontekstowe (osadzone w treści, a nie w nawigacji) przenoszą znacznie więcej wartości niż linki sitewide. Link Planner działa dokładnie w tym duchu – rekomenduje linki, które mają sens tematycznie i biznesowo.

Jak klastry tematyczne pokazują strukturę topical authority?
Klastry to automatycznie wykrywane grupy stron, które są blisko siebie semantycznie w przestrzeni embeddingów. Dla każdego klastra liczymy zestaw metryk:
- liczbę stron w klastrze,
- łączne kliknięcia i wyświetlenia,
- średni CTR i pozycje,
- średni dystans od centrum,
- spójność wewnętrzną klastra (cohesion),
- rozkład bucketów (ile stron Keep, Grow, Relocate, Prune).
Dzięki temu widać, które klastry tematyczne faktycznie budują topical authority (dużo stron blisko centrum, z ruchem i wartością), a które są peryferyjne (daleko od centrum, bez ruchu).
Typowy insight z analizy klastrów: serwis e-commerce ma silny klaster poradników o wyborze produktów (20 stron, 80% ruchu), ale klaster stron kategorii i produktowych (15 stron, 5% ruchu) jest rozproszony i daleko od centrum. Strategia: dobudować linkowanie z poradników do kategorii, rozbudować opisy kategorii o sekcje odpowiadające na zapytania z GSC, wzmocnić kontekst semantyczny stron transakcyjnych.
Semgence stosuje tę analizę klastrów jako punkt wyjścia do budowania content planów. Zamiast planować artykuły „od słowa kluczowego”, planuje się je „od luki w klastrze” – identyfikując miejsca, gdzie klaster tematyczny potrzebuje dodatkowej treści, żeby lepiej pokryć temat.

Jakie dane wchodzą do pipeline analizy?
Analiza wymaga czterech źródeł danych, z których każde wnosi inną perspektywę.
Screaming Frog dostarcza crawl serwisu – listę URL-i z ich statusami, tytułami, opisami, nagłówkami, liczbą słów. To surowy materiał, z którego budowane są embeddingi. Bez crawla nie ma mapy.
Model embeddingów (np. text-embedding-3-small od OpenAI) zamienia tekst reprezentatywny każdej strony na wektor semantyczny. Embeddingi pozwalają mierzyć podobieństwo stron, dystans od centrum, budować klastry i szukać najbliższych sąsiadów.
Google Search Console dostarcza warstwę ruchu i zapytań – kliknięcia, wyświetlenia, CTR, pozycje na poziomie strony i zapytania. Dane z GSC nakładane na mapę embeddingów dają obraz popytu.
GA4 (opcjonalnie) dodaje metryki zaangażowania i konwersji – sesje, zaangażowane sesje, engagement rate, konwersje, przychód. To warstwa biznesowa, która pomaga rozróżnić ruch wartościowy od ruchu pustego.
Pipeline jest zautomatyzowany i składa się z kilku kroków. Na początku admin wybiera projekt i crawl z Screaming Frog. Panel pokazuje dostępne crawle z datą, liczbą URL-i, statusem i informacją, czy dany crawl ma już przeliczone embeddingi. Po wybraniu crawla pipeline eksportuje dane (przede wszystkim Internal:HTML), filtruje strony do sensownych HTML-i z kodem 2xx/3xx, buduje tekst reprezentatywny dla każdej strony, pobiera dane z GSC (na poziomie page i page-query), liczy embeddingi i zapisuje je do bazy razem z modelem, wymiarem i hashem tekstu. Na koniec liczy site center, dystanse, projekcję 2D, klastry i buckety strategiczne.
Ważny detal techniczny: nie każda strona z crawla trafia na mapę. Pipeline filtruje URL-e, żeby analiza obejmowała tylko strony, na których praca SEO ma sens. Dla linkowania filtrowanie jest jeszcze bardziej rygorystyczne: usuwane są paginacje, tagi, kategorie, autorzy, feedy, attachment, wp-json, search, URL-e z parametrami i strony utility. Dane zapisywane są w bazie, więc nie trzeba liczyć wszystkiego od zera przy każdym otwarciu panelu – można wracać do starych runów, porównywać je i eksportować wyniki.

Jak porównywać zmiany topical authority w czasie?
Jednorazowa analiza to za mało. Topical authority zmienia się wraz z każdą publikacją, aktualizacją treści i zmianą w wynikach wyszukiwania. Dlatego narzędzie pozwala porównywać runy – przeliczenia wykonane na różnych crawlach w różnym czasie.
Porównanie dwóch runów pokazuje:
- czy strona przesunęła się bliżej centrum (wzmocniony kontekst tematyczny),
- czy zmieniła bucket (np. z Prune na Grow po rozbudowie),
- czy klaster się powiększył lub zmniejszył,
- czy SiteFocus wzrósł (serwis stał się bardziej spójny) czy spadł (rozproszenie),
- jak zmieniły się kliknięcia i wyświetlenia w kontekście struktury semantycznej.
To zamienia jednorazowy audyt w ciągły monitoring. Po wdrożeniu zmian contentowych uruchamia się nowy crawl i przeliczenie, a potem porównuje z poprzednim stanem.
W praktyce agencyjnej Semgence wykorzystuje porównania runów jako podstawę raportów before/after dla klientów. Zamiast mówić „opublikowaliśmy 5 artykułów”, można pokazać: „klaster audytu SEO przesunął się o 0.15 bliżej centrum, money page /audyt-seo/ zmieniła bucket z Grow na Keep, a SiteFocus content wzrósł z 0.62 do 0.71.”
To zamienia subiektywne wrażenia („chyba jest lepiej”) w mierzalne fakty. Klient widzi, że działania contentowe nie są abstrakcyjnym „pisaniem tekstów”, ale precyzyjnym budowaniem struktury tematycznej, która przekłada się na widoczność stron, na których mu zależy.

Jak interpretować typowe wzorce na mapie topical authority?
Mapa nie jest abstrakcją – pokazuje konkretne problemy strategiczne. Oto najczęstsze wzorce, jakie widzimy w audytach.
Money pages na obrzeżach mapy. Strony biznesowe nie są częścią tematycznego centrum. To jeden z najczęstszych problemów w serwisach usługowych – firma ma 50 artykułów blogowych i 5 stron usługowych, a strony usługowe to kilka zdań z formularzem kontaktowym. W takiej sytuacji embeddingi stron usługowych będą daleko od centrum, bo nie mają wystarczającej gęstości semantycznej. Rozwiązanie: dobudować linkowanie z poradników, rozbudować treść o sekcje odpowiadające zapytaniom, wzmocnić kontekst semantyczny.
Edukacyjne poradniki w centrum i 99% kliknięć. Content top-of-funnel wykonuje całą pracę SEO, ale serwis nie konwertuje. Rozwiązanie: Link Planner do przeniesienia autorytetu na strony bottom-of-funnel, sekcje „co dalej” w poradnikach, CTA do usług.
Duży klaster z ruchem, ale niska wartość. Serwis ma popularny temat, który nie wspiera biznesu. Może rozmywać topical authority, ale może też być dobrym źródłem linków. Rozwiązanie: przenieść użytkownika do stron wartościowych kontekstowymi linkami wewnętrznymi.
Outlierzy bez ruchu. Tematy poboczne, słabe dopasowanie do strategii. Rozwiązanie: sprawdzić, czy temat jest strategiczny. Jeśli nie – konsolidacja, noindex albo usunięcie. Jeśli tak – zbudować osobny hub i linkowanie.
Core pages bez kliknięć. Temat jest centralny, ale strona nie łapie popytu. Problem może tkwić w intencji, tytule, strukturze albo linkowaniu. Rozwiązanie: sprawdzić zapytania z GSC, poprawić title i H1, dodać sekcje odpowiadające intencjom użytkowników.
Na mapie semgence.pl (przeliczenie #31 z 30.05.2026, 339 stron, 3772 kliknięcia) widać te wzorce wyraźnie. Centrum serwisu tworzą artykuły z klastra SEO i content marketingu – to strony, które mają zarówno bliskość semantyczną, jak i ruch. Strony usługowe, które przeszły rozbudowę (np. /audyt-seo/, /pozycjonowanie-ai/), przesunęły się bliżej centrum w porównaniu z wcześniejszymi runami. Strony, które nie zostały jeszcze zoptymalizowane, nadal są w strefie ROZSZERZENIE lub PERYFERIE – co jasno wskazuje, gdzie skupić następne działania.
Czego pomiar topical authority nie zastępuje?
Zanim wyciągniesz zbyt daleko idące wnioski, warto uściślić, co pomiar topical authority daje, a czego nie.
Topical authority to nie jest to samo co siła profilu linkowego. Metryki typu DR (Domain Rating) w Ahrefs mierzą ilość i jakość linków zwrotnych prowadzących do domeny. To ważne, ale nie mówi nic o tym, czy serwis pokrywa temat kompleksowo.
Topical authority to nie jest też liczba artykułów na dany temat. Można opublikować 100 artykułów o SEO, ale jeśli każdy z nich to 300 słów bez głębi, bez powiązań i bez własnej perspektywy, to nie buduje autorytetu. Buduje szum.
Topical authority to nie jest wynik, który Google oficjalnie komunikuje. Nie ma w GSC zakładki „Twój topical authority score”. To koncept analityczny, który pomaga zrozumieć, dlaczego jedne serwisy rankują łatwiej niż inne na nowe frazy w swoim obszarze. Google potwierdza to pośrednio – przez wytyczne dotyczące E-E-A-T, Helpful Content System i liczne wypowiedzi zespołu Search Quality.
Badania Kevina Indiga i SISTRIX po aktualizacjach rdzeniowych w latach 2023-2024 pokazały wyraźnie, że serwisy, które traciły widoczność, miały wspólny wzorzec: szeroki zakres tematów pokrytych płytko. Serwisy, które zyskiwały, były wąsko wyspecjalizowane i pokrywały swój temat z głębią i wewnętrzną strukturą.
Co pomiar topical authority zmienia w strategii SEO?
Analiza topical authority zmienia sposób myślenia o SEO z taktycznego na strategiczny. Zamiast optymalizować pojedyncze strony pod pojedyncze frazy, patrzymy na serwis jako system.
Po pierwsze: treść powinna budować kontekst, nie tylko zbierać ruch. Każdy nowy artykuł powinien wzmacniać istniejący klaster, nie tworzyć nowy oderwany temat. Zanim napiszesz artykuł, sprawdź, czy pasuje do klastra, który chcesz wzmocnić.
Po drugie: linkowanie wewnętrzne to mechanizm transferu autorytetu. Linki kontekstowe w treści przenoszą wartość semantyczną i ruch z silnych stron na słabe. Link Planner automatyzuje szukanie najlepszych par source-target, ale zasada jest prosta: linkuj z treści, które mają ruch, do treści, które mają wartość biznesową.
Po trzecie: pruning jest tak samo ważny jak tworzenie. Strony, które nie generują ruchu i nie mają wartości biznesowej, aktywnie szkodzą topical authority. Dodają szum semantyczny, rozpraszają crawl budget i rozmywają sygnały tematyczne. Regularne przeglądanie bucketa Prune i podejmowanie decyzji (aktualizuj, konsoliduj albo usuń) to higiena, bez której nawet najlepsza strategia contentowa traci efektywność.
Aleyda Solis z Orainti pisała o tym w kontekście „content efficiency” – nie chodzi o to, ile treści publikujesz, ale ile z tych treści faktycznie pracuje na Twoje cele. Mapa topical authority to narzędzie, które pozwala to zmierzyć.
Jak przedstawić wyniki analizy topical authority klientowi?
Panel Topical Authority Intelligence pozwala zbudować czytelną narrację w kilku krokach, które klient rozumie bez znajomości embeddingów czy cosine distance.
Narracja wygląda tak: „To jest semantyczne centrum Twojego serwisu – główne tematy, wokół których Google Cię rozpoznaje. Te strony faktycznie generują ruch – i w większości to poradniki edukacyjne. Te strony mają wartość biznesową, ale są niewidoczne – Twoje money pages potrzebują wsparcia. Te klastry budują topical authority – tu jesteś mocny. Te strony są poboczne i nie wspierają strategii – kandydaci do pruningu. Tu powinniśmy rozbudować content. Tu powinniśmy dobudować linki. Po kolejnym crawlu porównamy, co się zmieniło.”
To jest dobra baza do onboardingu SEO, audytu contentu, strategii topical authority, planu linkowania wewnętrznego i raportów before/after. Eksporty z panelu (markdown report, CSV mapy, CSV link planner, CSV query) pozwalają przenieść dane do dowolnego narzędzia projektowego.
Klient nie musi rozumieć, jak działają embeddingi. Musi rozumieć, że jego strona usługowa jest daleko od centrum, jego blog jest blisko centrum i ma ruch, a linkowanie z bloga do usługi może przenieść widoczność tam, gdzie jest mu potrzebna. To jest język, w którym mapa topical authority komunikuje wartość.

Podsumowanie: od abstrakcji do mapy decyzji
Topical authority przestaje być abstrakcją w momencie, kiedy zamienisz treści na embeddingi, nałożysz na nie dane o popycie z GSC i podzielisz strony na buckety decyzyjne. Wtedy widać, gdzie serwis ma autorytet, gdzie ma ruch, gdzie ma wartość – i gdzie są blind spoty.
Żeby zmierzyć topical authority, trzeba:
- zamienić treści na embeddingi i zmierzyć ich wzajemne relacje,
- wyznaczyć site center i distance bands,
- nałożyć dane o popycie z Google Search Console,
- dodać warstwę wartości biznesowej,
- podzielić strony na buckety Keep/Grow/Relocate/Prune,
- zbudować rekomendacje linkowania oparte na bliskości semantycznej i query overlap,
- porównywać zmiany w czasie.
Semgence zbudowało Topical Authority Intelligence, żeby ten proces był powtarzalny i mierzalny dla każdego klienta. Zamiast jednorazowego audytu dostajemy ciągły monitoring, w którym każda zmiana contentowa ma swój przed i po.
Jeśli chcesz zobaczyć, jak wygląda mapa topical authority Twojego serwisu, skontaktuj się z nami – przygotujemy analizę na podstawie crawla i danych z Google Search Console. Ale musisz nam te dane udostępnić.
FAQ
Czym jest topical authority?
Topical authority to zdolność serwisu do wyczerpującego pokrycia danego tematu treściami, które Google traktuje jako wiarygodne. Więcej o samym koncepcie piszemy w artykule Topical Authority – czym jest?.
Jak zmierzyć topical authority za pomocą embeddingów?
Dla każdej strony liczy się embedding (wektor semantyczny), potem średni wektor całego serwisu (site center) i dystans każdej strony od tego centrum. Strony blisko centrum budują autorytet, strony daleko go rozmywają. Analizę uzupełnia się danymi z GSC i wartością biznesową.
Co to jest site center?
Site center to średni wektor semantyczny wszystkich stron w serwisie. To „tematyczny środek ciężkości” – punkt, wokół którego skupiają się główne tematy. Im więcej stron strategicznych jest blisko centrum, tym silniejszy topical authority.
Czym się różni SiteFocus content od SiteFocus demand?
SiteFocus content analizuje spójność tematyczną treści (na podstawie embeddingów). SiteFocus demand analizuje spójność popytu (na podstawie danych z GSC). Rozjazdy między tymi wskaźnikami wskazują problemy strategiczne.
Co oznaczają buckety Keep, Grow, Relocate i Prune?
Keep to strony z wysokim ruchem i wartością – filary do utrzymania. Grow to strony wartościowe, ale bez ruchu – największe szanse. Relocate to strony z ruchem, ale bez wartości – dobre źródła linków. Prune to strony bez ruchu i bez wartości – kandydaci do konsolidacji lub usunięcia.
Jak Link Planner wybiera pary stron do linkowania?
Link Planner łączy bliskość semantyczną (cosine distance), query overlap z GSC, intent match i wartość biznesową targetu. Każda rekomendacja ma uzasadnienie z konkretnymi shared queries i wynikiem scoringu.
Jak często powinno się mierzyć topical authority?
Po każdej większej zmianie contentowej – publikacji nowych artykułów, aktualizacji stron, dodaniu linków. W praktyce agencyjnej sprawdza się cykl miesięczny lub kwartalny.
Czy embeddingi to to samo co analiza TF-IDF?
Nie. TF-IDF mierzy częstość słów na poziomie leksykalnym. Embeddingi operują na poziomie semantycznym – rozumieją, że „samochód” i „auto” to podobne koncepcje. Dlatego embeddingi lepiej oddają tematyczne relacje między stronami.
Czy topical authority dotyczy tylko dużych serwisów?
Nie. Nawet serwis z 30-50 stronami ma strukturę semantyczną, która wpływa na to, jak Google go postrzega. Dla mniejszych serwisów analiza jest prostsza w interpretacji, bo mapa jest czytelniejsza.







